PyTorch DL for NLP -bag of wordsで英語とスペイン語を分類-
前回、DL for NLPを見据えてPyTorchの概要に触れました。
今回は公式の「Deep Learning with PyTorch」に沿って進めます。コードは全てこちらのものです。
はじめにPyTorchがどのようにネットワークを構築しているのか確認します。
最後にまとめとしてbag of wordsを用いて言語の分類を行います。
目次
環境
- MacBook Pro (Retina, 15-inch, Mid 2015)
- macOS High Sierra 10.13.5
- Python 3.6.3
- PyTorch 0.4.0
ディープラーニングの構成要素
ディープラーニングは以下のような要素(アフィン写像やsoftmax)などをネットワークの構成要素として組み合わせて構築します。
アフィン写像
以下のように線形変換と平行移動を合わせたものをアフィン変換と呼びます。
![]()
以下のコードはまずnn.Linear()でネットワークを定義しています。ここで5×3の行列が重みとして初期化されています。
次にtorch.randn()で適当な入力データが定義されています。
lin = nn.Linear(5, 3) data = torch.randn(2, 5)
このネットワークlinにdataを入力すると、2×3の出力が得られます。

また、nn.Linear()のソースコードを見るとweightというインスタンス変数を持っているようなので表示してみます。
これが重みとして使われているみたいです。ニューラルネットワークを学習させるにはこのパラメータを更新していく必要があります。

非線形
はじめに、ネットワークにアフィン写像を複数組み込んでもネットワークは強力にならないことに触れています。
下に示すように、アフィン写像のアフィン写像は別のアフィン写像に過ぎないからです。
![]()
もしネットワークを複雑にしたかったら非線形な演算を組み込む必要があります。
ただし、ニューラルネットに組み込む非線形な関数は勾配が計算しやすいものである必要があります。
そのような性質を持つ非線形な関数としてtanh(x)やσ(x)、ReLU(x) などが挙げられています。
ここではReLU関数の挙動を確認しました。
ReLUは正の入力はそのまま、負の入力は0にします。

グラフにするとこんな感じです。

Softmax
softmaxは通常ネットワークの出力の直前に適用されます。
具体的には以下のような式になります。
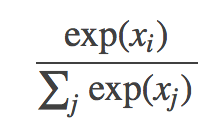
出力はそれぞれの要素が非負、合計が1のベクトルになります。
これによってクラス分類が比較しやすくなります。
目的関数
損失関数、コスト関数などとも呼ばれます。
ネットワークはこの目的関数を最小化するように学習します。
深くは触れませんが、定性的に説明すると、
もしモデルが確信度高く予想したにも関わらず答えが外れていたら目的関数が大きくなるように設定します。
目的関数の例としてここではnegative log likelihood(負の対数尤度)が挙げられています。
最適化と訓練
forwardが一巡したらパラメータの更新が行われます。
損失関数L(θ)を偏微分したものに学習率ηをかけたものをθから差し引くことで更新が完了します。
(以下の例はSGD、多分)
![]()
ただユーザは最適化アルゴリズムについて詳しく知らなくてもPyTorchのtorch.optimパッケージを使えば簡単にAdamやRMSPropなどの強力なアルゴリズムを実装することができます。
具体的にどのようなアルゴリズムが提供されているかはソースを確認してください。
PyTorchでネットワークを構築してみる
ここではbag-of-wordsを使って英語とスペイン語をロジスティック回帰で分類するネットワークを構築します。
Bag-of-Words (BoW)
Bag-of-Wordsとは文書に含まれる単語の出現回数をカウントしたものです。
例えば「hello」、「world」にそれぞれ0、1とインデックスを貼った場合、
「hello hello hello hello」という文書は[4, 0]と表現され、
「hello world world hello」は[2, 2]と表現されます。
このベクトルをBoWベクトルと呼びます。
ロジスティック回帰
二値分類問題を解くアルゴリズムの一つ。
詳細は割愛しますが、出力が0から1の範囲に収まります。
その値に応じて0もしくは1であることを判定します(ここでは0ならスペイン語、1なら英語)。
実装 -モデル構築-
それでは実装を見ていきます。
なおJupyter Notebookが公式ページ最下部で配布されているのでぜひご自分の環境で試してみてください。
まず英語、スペイン語それぞれで単語のリストを作りラベルと共にセットにします。
学習用とテスト用を作ります。
先ほど作った文章からユニークな単語を取り出し、word_to_ixに入れます。
keyが単語、valueはインデックスになります。
word_to_ixの中身はこんな感じになります。
単語に重複がなく、それぞれにインデックスが振られています。
今回の言語資源全体で語彙数は26であることがわかります。
![]()
それぞれの文書のBoWはこの辞書に従って作られます。
次にモデルを定義します。
とてもシンプルでここではBoWベクトルxにアフィン写像を施したのちにlog softmaxを取ります。
学習の過程でこのAとbというパラメータが更新されていきます。
![]()
上記の式をコードにすると以下になります。
ちなみにlog_softmax()はlog(softmax())と同じですが、後者だと計算が遅く計算が不安定なので、別の計算方法を用いたlog_softmax()の使用を推奨していました。詳しくは以下のページやソースコードを参照してください。
損失関数はNLLLoss(negative log likelihood)最適化アルゴリズムにはSGD(stochastic gradient descent)が採用されています。
それぞれの詳しい説明は公式のページやソースコードを参考にしてください。
BoWベクトルを作る関数も定義します。文章(単語のリスト)と先ほど作ったword_to_ixを入力するとBoWベクトルを返します。
試しにdataの最初の文me gusta comer en la cafeteriaからBoWベクトルを作り、モデルに突っ込んで出力を取得しています。
ここでは学習を回さないためにtorch.no_grad()を使っています(詳しくはこちら)。
出力は以下のようになりました。
![]()
ネットワークに渡すラベルはLongTensor型である必要があるので、ここら辺のコードで対応します。
![]()
実装 -学習前のoutput-
学習前に初期のパラメータではどのような出力が出るかチェックします。
以下のテストデータ2つをモデルに入力して、出力を取得します。
![]()
リストの0番目の値は文書がスペイン語であると思う確信度、1番目の値は英語の確信度です。
![]()
さらにcreoという単語に対する重みも取っています。
![]()
学習前は若干スペイン語に対して寄与が大きいです。学習後この差がより大きくなるかが注目点です。
![]()
実装 -学習-
では学習を開始します。
実装 -学習後のoutput-
学習後に再びテストデータの結果を見てみました。
テストデータの1つ目(スペイン語)では出力のindex 0の値が大きくなり、スペイン語であると予測できています。
同様に2つ目(英語)は逆にindex 1の値が大きくなり、英語であると予測できています。
単語creに対応するパラメータもよりスペイン語に対する寄与が高くなるように学習できていました。

まとめ
以上、ここではPyTorchでのネットワークの構成要素を理解し、実際にbag-of-wordsを特徴量としたロジスティック回帰を解いてみました。
学習のStep4のパラメータの更新あたりが難しかったのでよく中身を理解したいです。
参考
- Deep Learning for NLP with Pytorch — PyTorch Tutorials 0.4.0 documentation
- ReLU – Machine Learning for Humans – TinyMind
- Bag of Words(単語の袋) & TF-IDF – Deeplearning4j: Open-source, Distributed Deep Learning for the JVM
- What is Logistic Regression? – Statistics Solutions
- torch.nn | PyTorch master documentation

