自然言語処理入門 -NLTKを使ってみる-
自然言語処理始めます。一から。
基本的なPythonに関する知識はある前提で話を進めます。
Python3を使って、こちらの書籍を参考に進めます。

目次
NLTKインストール
Pythonで自然言語処理をするためにNLTKを使います。
pip install nltk
インタプリタでダウンロード画面を開きます。
$ python import nltk nltk.download()
するとこのような画面が開かれるのでbookを選択してダウンロードします。
だいたい2,3分で終わります。
以降はJupyter Notebookを使ってNLTKの挙動を確認します。
今回はnltk.bookを使って書籍のテキストを扱います。
from nltk.book import *
9冊の書籍のテキストが読み込まれたみたいです。

Textクラス
参考書籍ではトントン進んでいきますが、まずはこのtext1というものがどういうものか確認します。
typeはnltk.text.Textという形式で単純なstrとは違うことがわかります。

Textクラスの具体的な実装についてはGithubの該当箇所を確認してください。
Textクラスはnameとtokensというインスタンス変数を持ちます。
nameはテキストの名前(ラベル)、tokensにはテキストを単語ごとに区切ってリストにしたものです。
メソッドには例として以下のようなものがあります。
- concordance(): 引数の単語が含まれる文を探す
- count(): 文章中に単語が出てきた回数を数える(listのcount()がtokensに適用される)
- common_context(): 複数の単語に共通する表現を見つける
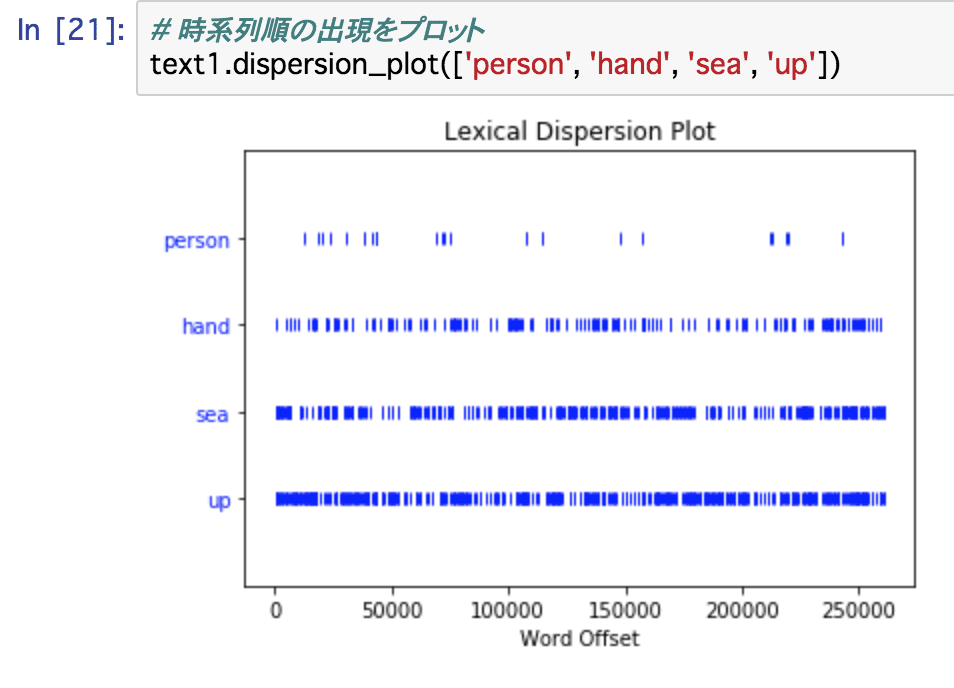
- dispersion_plot(): 時系列に沿って単語の出現をプロットする
- index(): 引数の単語が初めて文章中に出現するインデックスを取得する(listのindex()がtokensに適用される)
- similar(): 似たような分布の単語を見つける
- babelize_shell(): 2言語間の翻訳を平衡状態(Equilibrium)になるまで繰り返す。書籍で紹介されているが廃止された。代わりのサービはこちら。
dispersion_plot()ではこのようなプロットが表示されます。
similar()は意味的に似たものを探すメソッドではないことに注意です。
文章構造の中で似たような位置に収まるものを探してくるようです。
なので引数largeに対しては、一番にsmallが来ています(類似度が高いものから羅列される)。
その後大きさや度合いを表現する単語、他にも形容詞などが続きます。

テキストに含まれる単語の数はlen(text)で取得できます。これはtext.tokens(リスト)の要素数と同じです。

ユニークな単語数(ここでは語彙と定義)を取るにはset()を使います。
つまりtext1「Moby Dick by Herman Melville 1851」には単語が260819個含まれますが、ユニークな単語数すなわち語彙数(異なり語、異なりアイテムとも表現)は19317であることがわかりました。

FreqDistクラス -頻度分布-
入門 自然言語処理では以下のコードで頻出単語50を取得できるとのことですが、
fdist1 = FreqDist(text1) vocabulary1 = fdist1.keys() vocabulary1[:50]
Python3で上記コードを実行すると、タイプエラーが発生します。
TypeError: 'dict_keys' object is not subscriptable
これはPython2ではdict.keys()でlistが返ってきますが、Python3ではdict_keysというオブジェクトが返るように変更されたからです。
以下のようにlist化すればlistオブジェクトとしてインデックス指定できますが、
list(fdist1.keys())[:50]
書籍に書いてあるように頻出順に取得することはできません。

FreqDistクラスはcollections.Counterクラスを継承したサブクラスなので、most_common()メソッドが使用できます。
本来やりたかった頻出順に単語を取得するには、以下のような処理を行いましょう。
fdist1 = FreqDist(text1) fdist.most_common(50)

このように書籍で「ん?」と思ったときは「Natural Language Processing with Python」の原著がウェブで公開、更新されているのでこちらを確認すると良いです。(英語が読めるならそもそもこれで勉強しても良いでしょう)
PlaintextCorpusReaderクラス -コーパスの読み込み-
NLTKには複数のコーパスが用意されています。
import nltk
emma = nltk.corpus.gutenberg.words('austen-emma.txt')
このようにして、コーパスの単語を読み込むことができます。
この時、プロキシオブジェクトであるLazyCorpusLoaderによって、PlaintextCorpusReaderインスタンスが生成されます。
PlaintextCorpusReaderクラスはCorpusReaderクラスのサブクラスです。
Textクラスで使ったconcordance()などのメソッドを使うには読み込んだ文書を用いてTextクラスを新しく生成する必要があります。
emma = nltk.Text(nltk.corpus.gutenberg.words('austen-emma.txt'))
PlaintextCorpusReaderクラスには以下のようなメソッドが利用可能です。
余談
Githubで公開されているのでソースコードを遡るのも良いと思います。