PyTorch DL for NLP -単語埋め込み、n-gram、CBOW-
前回はBag-of-Wordsを使って文章を英語かスペイン語か分類しました。
Bag-of-Wordsは文書の特徴量でしたが、もっと細かく単語を特徴量として扱うにはどうすれば良いでしょうか。
今回は公式の以下のチュートリアルを参考に単語の特徴量について触れます。適宜スキップ、構成変更、意訳しているので、詳しく読みたい方は原文を参照してください。
コードは基本的に以下の公式のものを引用しています。
目次
環境
- MacBook Pro (Retina, 15-inch, Mid 2015)
- macOS High Sierra 10.13.5
- Python 3.6.3
- PyTorch 0.4.0
単語をどう表現するか
自然言語処理(NLP)では単語を特徴量として扱うことがほとんどのことです。
では単語をどのような特徴量として扱えば良いでしょうか。
そのまま文字列として扱うという方法がまず考えれられます。
しかしこの場合その単語がどのような意味を示しているか機械には理解できません。
(品詞などの情報を取得することはできますがあまり豊富な情報は読み取れません)
One hot表現
次にOne hot表現というのを考えてみましょう。
これは語彙数の大きさのリストを作り、リストのインデックスをそれぞれの単語に対応させます。
例えば、apple、orange、bananaの3つだけの語彙でリストを作った場合、appleやbananaという単語は以下のようなベクトルで表現されます。

ベクトルの大きさは語彙数と等しく、全ての単語はどこか一つの要素だけ1で残りは0となるようなベクトルで表現されます。
しかしこのOne hot表現は以下のような欠点を抱えています。
- 語彙数に応じてリストが大きくなる
- それぞれの単語間の表現に全く関係がない
意味的に近いものを関連づけられるような特徴量を設定するにはどうすれば良いでしょうか。
単語埋め込み(Word Embeddings)
単語を意味を伴った特徴量で表現できたら、単語間の関係性の取得に役立ちそうです。
そこで様々な意味的「属性」に対する点数で単語を表現してはどうでしょうか。
具体的には、「走れる」、「コーヒーが好き」、「物理学を専攻した」などの属性に対してどれだけ関連度合いが強いかを点数づけします。
以下に数学者と物理学者の属性をベクトルで表現しています。
いずれも「走れる(can run)」、「コーヒーが好き(like coffee)」に対して正の点数がついています。
一方で「物理学を専攻した(majored in Physics)」については数学者は-5.5、物理学者は6.4と他の2つに比べて差がついています。
引用: Word Embeddings: Encoding Lexical Semantics – PyTorch Tutorials 0.4.0 documentation

このように様々な属性に対する関連度合いをスコア化した特徴量を「単語埋め込み(Word Embeddings)」あるいは「分散表現(distributed representation)」と呼びます。
Word Embeddingsを用いることでそれぞれの単語(ここでは数学者と物理学者)の関連度合いも計算することができます。
例えば単語間の類似度の計算方法の一つにコサイン類似度があります。
以下のように計算され、単語が似ていれば1に近く、似ていなければ-1に近くなります。
引用: Word Embeddings: Encoding Lexical Semantics – PyTorch Tutorials 0.4.0 documentation
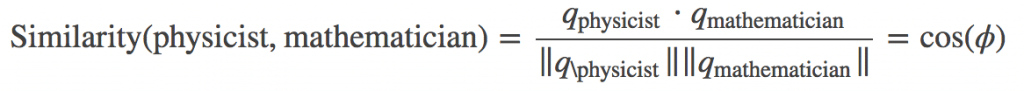
分散表現は単語間の類似度以外にも単語の演算を行うことができます。
KingからManの要素を引いてWomanの要素を足すとQueenの分散表現になるというものです。数式にすると以下のようになります。
(Kingの分散表現) – (Manの分散表現) + (Womanの分散表現) = (Queenの分散表現)
また、先ほどのOne hotベクトルのようにほとんどの要素が0の特徴量を疎(sparse)と表現するのに対して、Word Embeddingsのようにほとんどの要素が0でない特徴量を密(dense)と表現します。
しかしこのような意味的なスコアに基づく特徴量にも問題はあります。
どのような意味に関するスコアを採用するのか、どのようにスコア付けするのか、です。
ここではニューラルネットを用いることで自動的にこれらの値を決めることができることを確認します。
PytorchによるWord Embeddingsの実装
実装の前にWord Embeddingsについてもう少し細かくみてみます。
Word Embeddingsは|V| × Dの行列で表現されます。
Vは語彙数、Dは次元数でそれぞれの単語を幾つの次元で表現するかです。
torch.nn.Embeddingを使うことで単語埋め込みを実装できます。
公式ページの最下部からダウンロードできるJupyter Notebookを実行しながら解説します。
ここでは語彙は「hello」と「world」だけなのでV = 2です。
単語を表現する次元数として5を選択しています。
helloを表現するEmbeddingsをprintしています。これは初期値なので実行の度に変わります。
このベクトルを以降の学習を通して適切に設定(近い意味のものはコサイン類似度が高くなるように)します。
nn.Embeding()に対して単語のインデックスを入力するとその単語の分散表現が返って来ることがわかりました。
PyTorchでどのようにWord Embeddingsが表現されるか確認しました。
以下では学習を通じて適切なWord Embeddingsを求めます。
例: n-gram
n-gramとは連続するn個の要素のことを指します。この要素は単語以外にも形態素や文字が採用されることもあります。
ここでは連続するn個の単語から次に出現する単語を予測します。
またn=2の場合はbigram、n=3の場合はtrigramと特別に呼びます。
引用: Word Embeddings: Encoding Lexical Semantics – PyTorch Tutorials 0.4.0 documentation
例えば以下の例文のn-gramを作ってみます。
- Done is better than perfect.
n=2なら[(Done, is), (is, better), (better, than), ...]となります。
n=3なら[(Done, is, better), (is, better, than), (better, than, perfect), ...]となります。
n個の単語の塊を一つずつインデックスをずらしながら作っていく感じです。
trigramで予測するネットワークをコードにするとこんな感じです。
まず予測に使う単語数(コンテキスト)はtrigramなので3-1=2です。分散表現の次元数は10と設定されています。
最初の3つのtrigramは以下の通りです。
ここでは予想対象の単語(3つ目の単語)と予測材料の単語を([ word_i-2, word_i-1 ], target word)という形で表現しています。
[(['When', 'forty'], 'winters'), (['forty', 'winters'], 'shall'), (['winters', 'shall'], 'besiege')]
語彙がvocabで定義されています。文書で使われた単語がset型で(重複なく)まとめられました。
さらにこれらの単語をkeyにインデックスをvalueにする辞書word_to_ixを定義しました。
ちなみに語彙数len(vocab)は97でした。
ネットワークは以下の通りです。
模式図にするとこんな感じです。
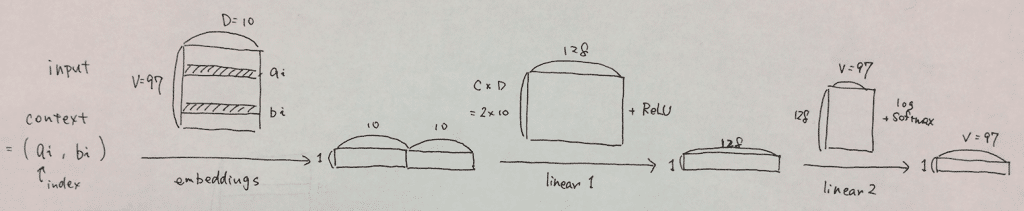
forwardの流れを解説します。
まずcontextのindexが2つ入力されます。
するとembeddings層は語彙全体の分散表現から該当する単語の分散表現を返します。ここでview((1, -1))で1行にしています(列数は自動)。ここではコンテキストサイズが2なので1×20になります。
linear1層は20×128の行列です。embeddings層の出力と計算して、1×128になります。さらにこれにReLU関数を適用します。
linear2層は128×97の行列です。よって計算結果は1×97になります。最後にlog softmax関数を適用して最終出力を得ます。
torch.nn.Embeddingについて詳しく知りたい方は公式を参照してください。
損失関数と最適化アルゴリズムは以下の通り。
学習を回してみましょう。ひとまず10epoch。
STEP1. コンテキスト(直前2つの単語)をあらかじめ設定したインデックスで表現し直します。
SETP2. PyTorchではネットワークの勾配が保存されるのでイテレーションを回すごとにリセットします。
STEP3. 先ほど解説したforwardの処理が行われ、返ってきたlog softmaxに対して損失関数を計算します。
STEP4. backwardが実行されパラメータが更新されます。
学習過程の可視化のためにエポック毎に損失関数の出力の和を取得しています。
tensor([ 522.7924])
から
495.8811
、あまりよく学習していないようです。学習に使ったテキストの量を考えればこの程度が妥当なのかもしれません。
試しに学習データの冒頭の2単語「And dig」を入力してみましょう。
続く「deep」が出ることを期待しますが、残念。「How」という予測が出ました。
文脈的にもあまり通らなさそうですね。
エポック数を100に増やしたところ、「And dig」に続く単語として「deep」が得られました。
過学習なのは間違い無いでしょうが、このネットワークで正しく学習が進みそうなのは確かめられました。
本来はトークナイズなどを挟むべきとも書いてあったので、精度が出ないのはしょうがないかもしれないですね。
後日大量のデータを使って試してみます。
例: Continuous Bag-of-Words (CBOW)
n-gramでは直前n個の単語から次の単語を予測しました。
CBOWでは前後n個の単語の集まりから真ん中に収まる単語を予測します。
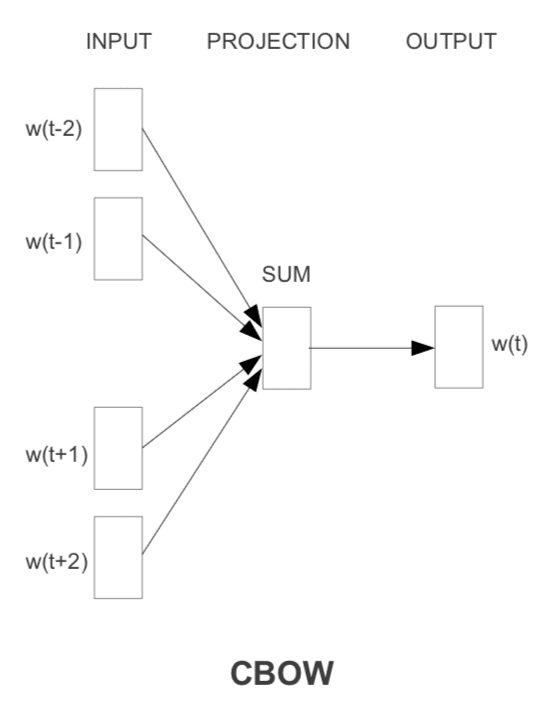
式にするとこのような感じです。
引用: Word Embeddings: Encoding Lexical Semantics – PyTorch Tutorials 0.4.0 documentation
n-gramと似ていますが、最大の違いはCBOWは順番を考慮しないという点です。
また順番を考慮しなくて良いということは並列的に処理が行えます。
n-gramでは1エポックの中でfor文を使って1コンテキスト毎ネットワークに投入していました。
CBOWでは一気に全てのBag-of-Wordsを入力できるので計算が早くすみます。
そのためCBOWで予め単語分散表現を取得した後に、計算がより複雑なモデルでより良い分散表現へと学習するというような使い方ができます。
コードを見ていきます、と思ったら「ネットワークに関しては自分で実装してみてくれ」とのことなので原著を当たったりしながら書いていきます。間違いがあったらTwitterにお知らせいただけると幸いです。
ちなみにCBOWの原著はTomas Mikolovによるこちらの論文です。
ひとまずPyTorchがガイドしてくれている部分のコードを読みます。
先ほどのn-gramと同じですね。違うのはコンテキストが前後2単語になっている点です。
n-gramの時に作ったtrigramsと同じですね。
予測材料のコンテキスト(前後2単語の合計4単語)のリストと予測対象の単語でセットにしています。
便利関数としてコンテキストを入力すると対応するインデックスを返す関数を用意してくれました。
ネットワークはこんな感じにしました。
入力がBag-of-Wordsになった以外はn-gramと同じです。
損失関数と最適化アルゴリズムも同じです。
こんな感じで学習させました。
エポック毎のlossを出力したらn-gramと比較して明らかに減少が早いですね。
最後に学習の成果を確認しましょう。
「Computational processes are abstract beings」の真ん中の「are」を抜いたコンテキストを入力してみます。
見事に「are」を予測できました。
エポック10でもそれなりの結果が出たみたいです。
計算が早いのは納得ですが、精度がいいのはCBOWの特徴でしょうか?
単にn-gramより予測に使える情報が倍であるからにも思えます。n-gramでn=5にした時の予測精度と学習時間をCBOWと比較してみたいです。
参考
- Word Embeddings: Encoding Lexical Semantics – PyTorch Tutorials 0.4.0 documentation
- N-gramモデルを利用したテキスト分析
- n-gram – Wikipedia
- Use Argmax to index tensor – PyTorch Forums
