NER評価方法
precision, recall, f1-scoreの定義について悩んだのまとめました。
割とバラエティに富んだ評価手法がありました。
目次
前提
precision, recall, f1-scoreについては理解している前提でまとめます。
曖昧な方はこちら。
NERにおける正答とは
これまで論文読んだり人のコード使いながら、F1値眺めてふんふんと比較していたけど、自分で評価しようと思った時にわからなくなったので調べました。
POS-taggingなどでは予測と答えを突き合わせれば良いです。単語分割はどちらでも同じですから単純にタグだけを比較すればオッケーです。
しかし、NER(Named Entity Recognition)ではタグだけでなく単語の範囲も問題になります。
- タグは合っているけど範囲が違ったり、範囲は合ってるけどタグが合っている場合はどう扱うのか?
- 開始点は合ってるけど終止点が間違っている場合は?
など答えられませんでした。
以下の記事で丁寧にまとめてありました。
NERシステムの出力パターン
以下では「エンティティでないもの」を「O」と表現します。
シンプルに評価する時は3つのパターンだけ考慮すれば良いそうです。
- エンティティ、Oを正しく識別:true positive, true negative
- Oをエンティティと誤識別:false positive
- エンティティをOと誤識別:false negative
これらを用いてシンプルにprecision, recall, f-scoreを算出します。
しかし中には以下のようなパターンもあります。
- エンティティの種類を誤識別(範囲を正しく識別)
- エンティティの範囲を誤識別(種類を正しく識別)
- エンティティの種類と範囲を誤識別
こういった込み入ったパターンに対しては様々な評価スキームがあるそうです。
- CoNLL (Computational Natural Language Learning)
- 1~3だけで評価
- 4~6のようなパターンは評価の対象外とする
- MUC (Message Understanding Conference)
- 独自の指標を利用(カッコ内は上述の1~6に対応)
- Correct:エンティティの種類、範囲を正しく識別(1のエンティティのみ)
- Incorrect:エンティティの種類、範囲を誤識別(6)
- Partial:エンティティの種類、範囲を一部正しく識別(4, 5)
- Missing:エンティティをOとして誤識別(3)
- Spurius:Oをエンティティとして誤識別(2)(sprius=偽造の)
- SemEval (Semantic Evaluation)
- MUCを使って以下の指標を評価(カッコ内は上述の1~6に対応)
- Strict:エンティティの種類、範囲を正しく識別(1のエンティティのみ)
- Exact:エンティティの範囲を正しく識別(4)
- Partial:エンティティの範囲を一部正しく識別(6のうち範囲が被っているもの)
- Type:エンティティの種類を一部でも正しく識別(5に近い)
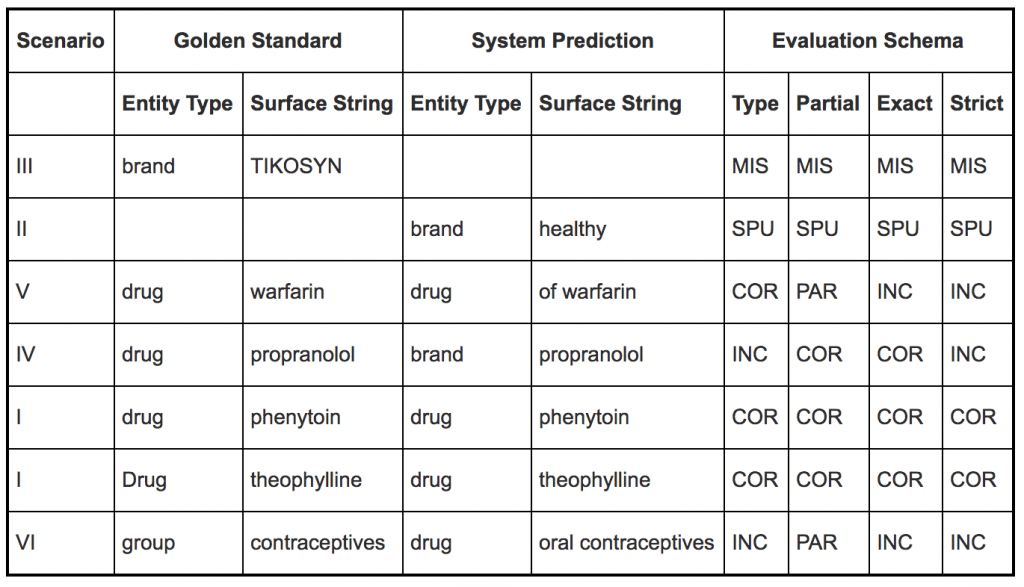
SemEvalの例がわかりにくいので画像で引用します。
Type, Partial, Exact, Strictという観点でMUCのCorrect, Incorrect, Partial, Missing, Spuriusを点数としてつけていく感じです(Partial被りがややこしい)。
おまけ
そんな感じ。今文字レベルのタグ付けをやっているので単語レベルをそのまま適用はできないけど、参考になりました。