PyTorch DL for NLP -LSTM-
前回は単語埋め込み(分散表現)を利用してn-gramやCBOWを用いて単語の予測を行いました。
今回は公式の以下チュートリアルを用いてLSTMについて理解します。
毎度のごとく、コードは上記リンクで公開されているものを使用しています。
目次
環境
- MacBook Pro (Retina, 15-inch, Mid 2015)
- macOS High Sierra 10.13.5
- Python 3.6.3
- PyTorch 0.4.0
Long-Short Term Memory Networks: LSTM
前回まで触れたモデルではネットワークは状態を考慮しませんでした。しかしNLPの入力データはシーケンシャルな単語(あるいは文字列、文章)なので明らかにそれまでの入力に関する情報が重要になってきそうです。
入力データ間の依存を考慮した古典的なモデルとしてはHidden Markov Model: HMM(隠れマルコフ連鎖)やconditional random field: CRF(条件付き確率場)などが知られています。
recurrent neural network: RNN(再起型ニューラルネットワーク)は状態を保つネットワーク、すなわち出力が次の入力に影響を持ちます。
図にすると以下のようになります。
シーケンシャルな系列データxを入力すると、系列hが出力されています。これを系列ラベリングと呼びます。
また、あるタイミングの入力が以降の出力に影響していることが模式的にわかります。
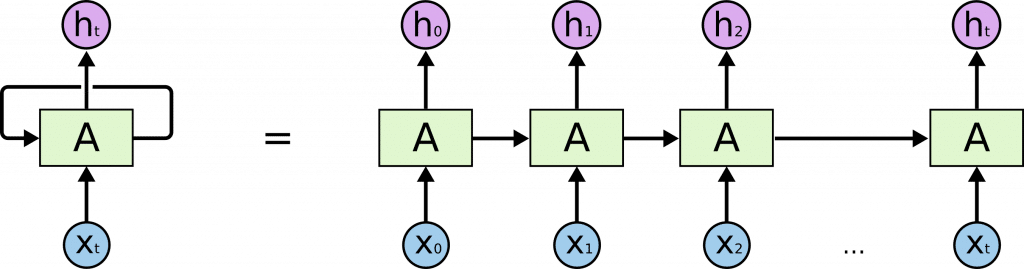
原理的に、RNNは長い文脈であっても以前の入力を保持して、予測材料として使えます。しかし実践的にはそうすることができませんでした。詳しくは触れませんが、勾配消失・爆発問題が起こってしまうためです。
LSTMは前述の問題を解決する手法として提案されたRNNの一種です。
あるタイミングの入力が後の出力に影響を与える点ではRNNと同じですが、その計算方法が異なります。
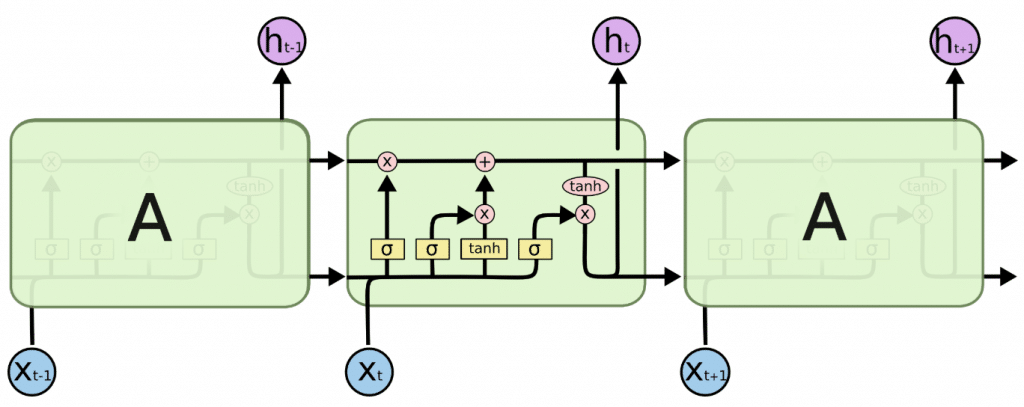
上の模式図を式にするとこうなります。
iは入力ゲート、fは忘却ゲート、oは出力ゲートと呼ばれます。
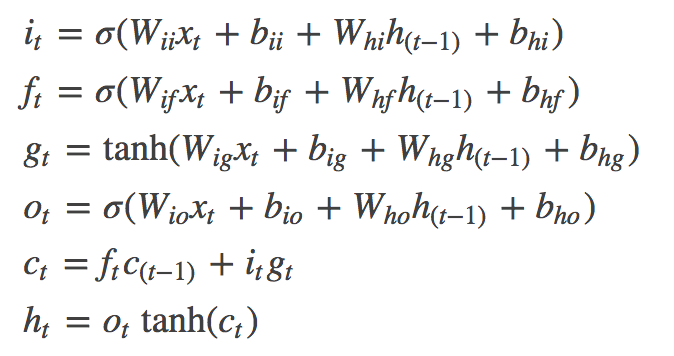
それぞれを先ほどの模式図に当てはめるとだいたいこんな感じです。
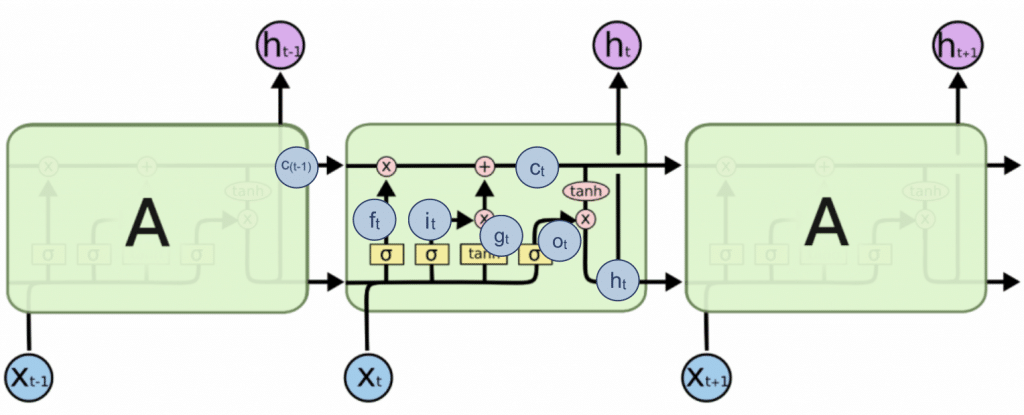
引用元のサイトでステップごとにどのような計算がされているか丁寧に解説してあるのでぜひ参照してみてください。
もっとわかりやすい図がこちらにあったので引用します。
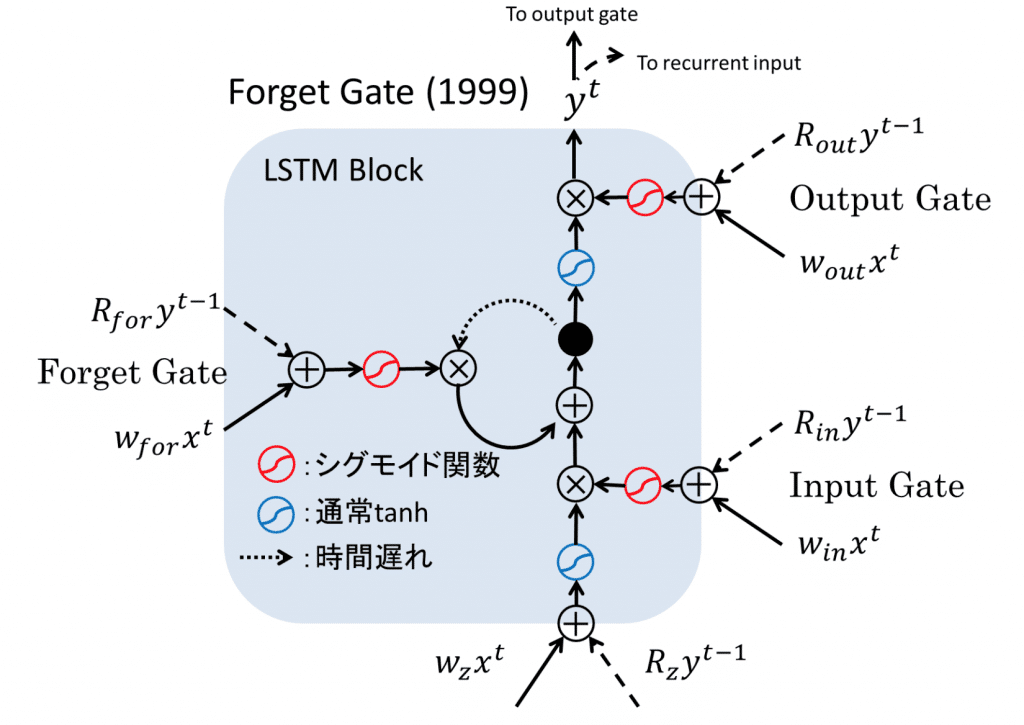
LSTMの登場によってRNNは音声や自然言語などの連続的データを用いた課題の解決に大きく貢献しました。
LSTM’s in Pytorch
では実際にPyTorchのLSTMの挙動を確認します。
以下はLSTMネットワークに対して連続データinputsをfor文で一つずつ入力する例です。
また以下のようにLSTMに入力データを一気に投入することができます。
この場合lstm()が返す2つの値のうちoutは各々の入力に対応する隠れ状態です(すなわち出力の導出に使われます)。
hiddenは最後の隠れ状態なので、outの最後の要素と一致することがわかります。
例: LSTMを用いたPart-of-Speech tagging
ここでは実際にLSTMを使ってNLPタスクを解いてみましょう。
対象タスクはpart-of-speech tagging: POS taggingです。POSは品詞のことです。
POS taggingは文章中の単語の品詞を判別するNLPタスクです。
ここで、wiを入力とします。Vは語彙の集合です。
![]()
yiをwiのラベル、![]() をwiに対する出力ラベルとします。Tはタグの集合です。
をwiに対する出力ラベルとします。Tはタグの集合です。
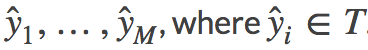
なお![]() は以下のようにして求めます。hiはhidden state(隠れ状態)です。
は以下のようにして求めます。hiはhidden state(隠れ状態)です。
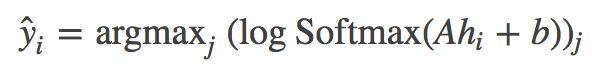
実際にコードを見ていきます。
まず前回までのように学習データの全ての単語を語彙として登録し、インデックスを紐付けます。
さらにタグ(DET、NN、V)もインデックスを作ります。
なおそれぞれ以下の品詞に対応しています。
- DET: 限定詞
- NN: 名詞(単数形)
- V: 動詞
モデルを構築します。
損失関数と最適化関数を設定します。
学習を回し、最後にtraining_data[0][0]すなわち['The', 'dog', 'ate', 'the', 'apple']という文章を入力してそれぞれのPOSを予測しています。
それぞれの3次元の出力はDET、NN、Vの品詞に対応しています。
もっとも値が大きい要素のインデックスは以下の通り0、1、2、0、1です。

したがってそれぞれの単語のPOSの予測は
- The: DET(限定詞)
- dog: NN(名詞)
- ate: V(動詞)
- the: DET(限定詞)
- apple: NN(名詞)
と予測できたことがわかりました。
もちろん、今回は学習データが小さかったり学習データをテストデータに使ったりしているのでLSTMの性能を計測するには改めて実験する必要があります。
Exercise: Augmenting the LSTM part-of-speech tagger with character-level features
練習課題として文字レベルのLSTMを課されています。
文字レベルでの解析は接辞による判断を加えられることが大きな利点です。
例えば英語では接尾辞「-ly」がつく単語は高い確率で副詞であると判断できます。
コードが書けたら公開します。
参考
- 再帰型ニューラルネットワーク: RNN入門 – Qiita
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Understanding LSTM Networks
- A Beginner’s Guide to Recurrent Networks and LSTMs
- わかるLSTM ~ 最近の動向と共に – Qiita
- 最近の自然言語処理 – SlideShare
深層学習
600ページに及ぶ書籍です。深層学習について歴史から理論まで細かく説明されています。まだ全部は読めていませんが、「第10章 系列モデリング:回帰結合型ニューラルネットワークと再帰型ネットワーク」を参考にしました。
本記事ではLSTMだけを解説しましたが、RNNについて深く知ることができます。
