Swampdog part13 -3Dセグメント機械学習調査-
医療分野でVR技術を活用しているHoloEyesのCTO谷口さんにお話を伺う機会がありました。
CT画像を3次元的に解釈して自動で臓器などをセグメンテーションする(立体版CNN?)という論文が出ているとのことだったので調査しながら周辺情報をメモします。
まだ基礎的な内容なので誰かしらが日本語でまとめているんですが、これからどんどんディープな内容に突っ込むなら英語不可避ですね。
久しぶりに論文読みました。と言ってもアブストだけでとりあえずざっくり概要把握しただけです。
あまり信用せず、詳しいことを知りたい方は原著を当たってください。
目次
Automatic Liver and Tumor Segmentation of CT and MRI
Volumes Using Cascaded Fully Convolutional Neural Networks
- 日付: 2017/02/23
- first author: Patrick Ferdinand Christ
- last author: Bjoern Menze
- 雑誌: Medical Image Analysis
- 対象: 肝臓とその病変
- 手法: Cascaded Fully Convolutional Neural Networks(CFCN)
- 概要: FCNでCT(2D)から肝臓をセグメントする。この肝臓に対して再度FCN次は病変をセグメントする。最後にがっしゃんこして3Dの結果を得る。(教師データは50ほどで良いらしい。)
- 原著: リンク
感想
とりあえずググって一番最初に出てきたやつ。
そもそもFCNがわからないのでさらにググる。
CNNは画像に対して何が写っているか、という1つの答えしか出力できませんでした。
FCNは画像内の全てのピクセルについて判定することで、複数のものが写っている画像にも対応できるとのことです。
R-CNNと何が違うん?って感じでしたが、以下のスライドでわかりやすく説明してありました。
ざっくりもざっくりに説明すると、
R-CNNは「物体検出」の一種。何がどこら”へん”に写っているかを判定(画像はFaster R-CNN)。
出展: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks

FCNは「セグメンテーション」の一種。ピクセル単位で何が写っているか判定(下はSDS)。

と言った感じでしょうか。
画像で見比べるとよくわかりますね。
単純に考えればセグメンテーションの方が好ましいですね。
分類の精度や学習コストなどで一長一短なのでしょうが。OsiriXのROIと相性が良さそうです。
この論文では2Dを順繰りに処理して最後に合体、という感じでした。
それがシンプルなやり方ですよね。
3次元のピクセル画像を扱っているものはないのかな。計算量が膨大になりそうですが。
まだよくわかんないので引き続き調査。
3D Segmentation in CT Imagery with Conditional
Random Fields and Histograms of Oriented Gradients
- 日付: 2011/09/18
- first author: Chetan Bhole
- last author: Christopher Pal
- 雑誌: Lecture Notes in Computer Science
- 対象: 腹腔臓器
- 手法: MRF + CRF
- 概要: MRFとCRFを用いて、腹腔内の臓器を3D的にセグメンテーションする。HOG特徴量を利用することでガッとセグメンテーションしてくれる。
- 原著: リンク
感想
結構前の論文なのでこの論文の後継を探せば目的のものが見つかるかも、です。
ちなみに今度はMRF、CRFってなんぞや。
- MRF (Markov Random Field): マルコフ確率場
- CRF (Conditional Random Field): 条件付き確率場
いずれもグラフィカルモデルの一種らしいです。
以下のスライドを参考にしてください。
つまりMRF・CRFはノードとリンクで関係を表記して(画像の丸がノード、線がリンク)、
着目したノードの状態を周囲のノードやリンクから判定するという考え方(?)。
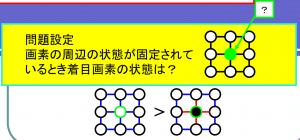
「これって画像をピクセル単位で見た時に使えそう」っていうところからCV(コンピュータビジョン)に使われているそうです。
感覚的にも理解できますね。
周りが赤色のピクセルばっかりの中にポツンと緑色のピクセルがあるのは不自然ですし。
画像のノイズ除去などに使われているそうです。
確率モデルのCVへの応用については以下のスライドが参考になりました。
ということでこの論文ではMRF、CRFにHOG特徴量(右から2番目)を併用することで、
ざっくりとしたマニュアルの分類(左から2番目)をもっと細かく分類してくれる(一番右)って感じ。
あんまり精度はよくないですね。
出展: 3D Segmentation in CT Imagery with Conditional Random Fields and Histograms of Oriented Gradients

そういう意味で一本目に紹介した論文のように、2DはFCNでセグメンテーションして、
それらの2Dを重ね合わせて3Dにする時にMRFを使うってのが良さげ。
ふんわり把握できてきました。
Three-Dimensional CT Image Segmentation
by Combining 2D Fully Convolutional
Network with 3D Majority Voting
- 日付: 2016/09/27
- first author: Xiangrong Zhou
- last author: Hiroshi Fujita
- 雑誌: International Workshop on Deep Learning in Medical Image Analysis (?)
- 対象: 全身
- 手法: FCN
- 概要: 3DのCTデータからいろんな角度で切った2D画像を冗長的に得る。それらに対してFCNでセグメンテーションをする。各ボクセルのラベルは多数決によって決定する。これにより89%の精度で
- 原著: リンク
感想
論文中にあった画像がわかりやすい。
x, y, zの3軸でスライスした画像を得て、これをFCNに投げる。
全てのボクセルに対してラベル候補が得られる(3つ得られるはず)ので、多数決でラベルを決定する。
ラベル情報を元に3Dモデルを作成する(ラベルごとに色分け)。
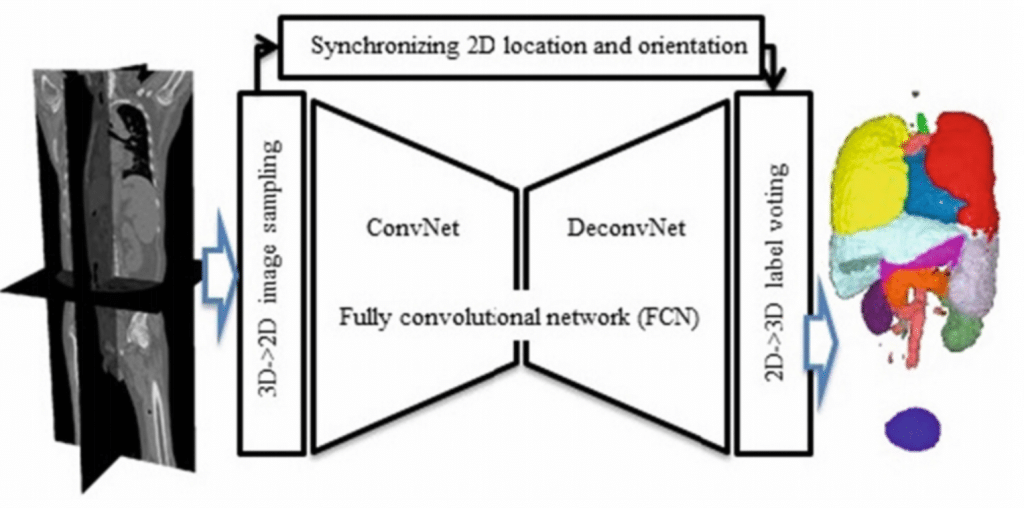
わかりやすい。
1軸でスライスを得ていってFCNを適用した時、組織の辺縁しか映らなかったら判定が難しそうだと思いましたが、これならある程度カバーできますね。
シンプルで理解しやすいです。
単純な多数決じゃなくてMRFを用いればもっと誤検出率下がるかな?
90%というと医療で用いるにはまだ怖いですね。参考資料程度にはなるといったところでしょうか。
今回はここまで。
今すぐ必要な知識ではないですが、将来的なところを見越して引き続き情報収集を続けます。
おまけ: MICCAI
あと調べていたらMICCAI (Medical Image Computing and Computer Assisted Intervention)という国際会議を見つけました。医用画像処理に特化しているようで、関心にピタリです。
今後追っていきます。今年の予定は以下のリンク先から。9月にカナダで開かれるらしいです。