SeleniumでPhantomJSを使ってスクレイピング
【2018/10/9 追記】
PhantomJSは2018年3月に更新が終了しました。
本記事のコードを実行しても以下のエラーが出るでしょう。
UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
今後はChromeなどを使うのが良いでしょう。試してみました。
【追記終了】
SPAではHTMLをロードした後にJavaScriptがページを生成します。
従って、単純にrequestsなどで取得したhtmlソースでは取得したい情報が得られません。
ここではSeleniumを使ってウェブブラウザを操作することで解決します。
目次
環境
- Mac
- Python 3.4.1
- selenium 3.8.0
SeleniumとPhantomJS
Selenium

Seleniumはウェブブラウザを操作するソフトウェアです。
例えば、ウェブページを開いてIDとパスワードを入力してログインする、ページの下までスクロールして読み込みを待つ、など単純にページを開くだけでなく操作を必要とするような場合に役に立ちます。
Seleniumが操作可能なブラウザはChrome、Firefoxなど多岐に渡ります。
PhantomJS

PhantomJSはヘッドレスなWebKitです。つまり画面がないブラウザのようなものです。
Seleniumのウェブドライバーとして選択可能です。
Selenium経由で操作することで、画面のないブラウザでJavascriptの挙動を考慮してウェブページを取り扱うことが可能です。
インストール
brew install phantomjs pip install selenium
PhantomJS経由でウェブページを取得する
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.PhantomJS()
url = 'http://google.com'
driver.get(url)
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
これであとはsoupを煮るなり焼くなり処理すれば良いです。
テスト
では、JavascriptでHTMLが書き換えられるウェブサイトを例にテストをします。
PLOS Oneの検索結果画面を例にとります。
cancerで検索してみると、このような画面になります。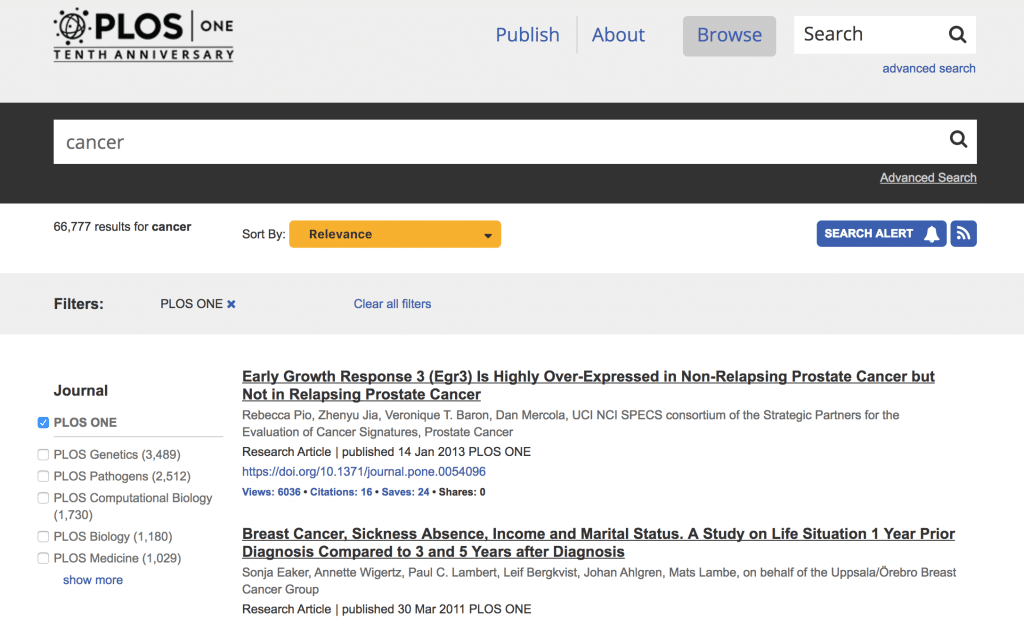
論文のタイトルが見えています。
検証ツールを使うと、searchResultsListの中にdt要素として格納されていることがわかります。
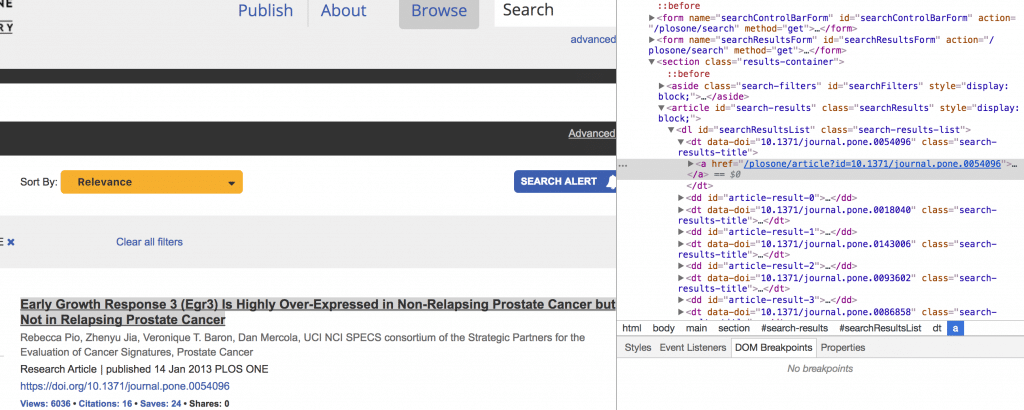
しかし、「ページのソースを表示」をしてみると中にはコードらしきものが入っていますが、実際のタイトルは記述されていません。

requests
これを単純にrequestsとBeautifulsoupで取得してみましょう。
import requests from bs4 import BeautifulSoup url = 'http://journals.plos.org/plosone/search?q=cancer&filterJournals=PLoSONE' html = requests.get(url).text soup = BeautifulSoup(html, "html.parser") target = soup.find(id='searchResultsList')
targetの中身を見てみます。
print(target) # None
中身は空でした。
Selenium + PhantomJS
ではSeleniumとPhantomJSを使ってみます。
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.PhantomJS()
url = 'http://journals.plos.org/plosone/search?q=cancer&filterJournals=PLoSONE'
driver.get(url)
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
target = soup.find(id='searchResultsList')
targetの中身を見てみます。
print(target) <dl class="search-results-list" id="searchResultsList"> <dt class="search-results-title" data-doi="10.1371/journal.pmed.1001200> <a href="/plosmedicine/article?id=10.1371/journal.pmed.1001200">Ovarian Cancer and Body Size: Individual Participant Meta-Analysis Including 25,157 Women with Ovarian Cancer from 47 Epidemiological Studies</a> </dt> ...
目的の要素が入っていました。
あとは必要に応じて加工してあげれば良いですね。
もっと詳しいことを知りたい方はPythonによるスクレイピング&機械学習がおすすめです。
SeleniumやPhantomJSの専門の話ではないですが、スクレイピング全般や作法、さらに機械学習の触りまで学習できて内容が広く勉強になりました。
参考
