Elasticsearch + Python 基本機能の確認
大量のテキストデータに対する検索を実装したかったので、全文検索について調べてみました。
ざっくりRDBMSと比べて全文検索が優れいてる点は検索速度、検索精度らしいです。
詳しい説明は他サイトを参照。
とりあえず触ってみようが今回の目的です。
目次
Elasticsearchインストール
登録が必要で面倒ですが、公式のビデオが参考になります。
まずJavaのバージョンを確認します。
java -version java version "1.8.0_102"
公式サイトからElasticsearchをダウンロードします。
解凍して、ディレクトリ内に移動してコマンドを打ちます。
bin/elasticsearch
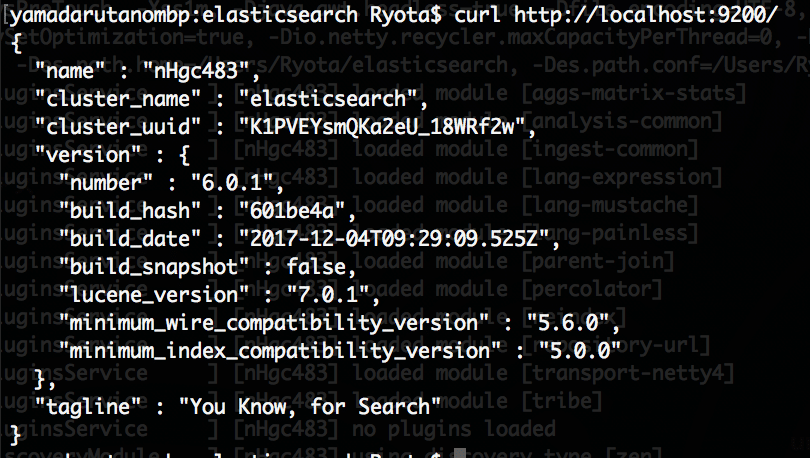
別のコンソールを開いてcurlでGETしてみましょう。
curl http://localhost:9200/
するとJSONが帰ってくるのでElasticsearchの起動を確認できました。
Elasticsearchは適当なところに移動しておきましょう。
実行ファイルを起動するとローカルの9200番に開かれるということです。
IndexとTyep
Elasticsearchに実際にデータを入れていく前にIndexとTypeの違いをまとめます。
RDBになぞらえてシンプルにIndex = DB、Tyep = Tableと説明されることがあるらしいですが、正確には違うらしいです。
とりあえずはそんな感じの認識で進めます。
細かい意味は以下のページを参考にしてください。
PythonからElasticsearchを利用してみる
公式のPythonチュートリアル、APIドキュメントを参考にします。
まずはpipでライブラリを入れます。
pip install elasticsearch
index(): ドキュメントの追加、更新
適当にPythonスニペットを書いていきます。
es = Elasticsearch()で特にオプションを記述しなければ、localhost:9200を見に行きます。
index()メソッドではドキュメントの追加、更新ができます。
引数にはindex、doc_type、bodyを必要とします。
この時点で指定したインデックス、タイプがなければ自動で作成されます。
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="my-index", doc_type="test-type", body={"key": "value"})
すると以下のような辞書が返ってきます。idは7P6CP2ABosfH4dF6PS98というのが振られたみたいです。
インクリメントでないのはRDBと違いますね。
これでmy-indexというインデックスにtest-typeというタイプで{“key”: “value”}というドキュメントが生成されました。
{'_id': '7P6CP2ABosfH4dF6PS98',
'_index': 'my-index',
'_primary_term': 1,
'_seq_no': 0,
'_shards': {'failed': 0, 'successful': 1, 'total': 2},
'_type': 'test-type',
'_version': 1,
'result': 'created'}
ちなみに、以下のようにidを指定してドキュメントを作成することもできます。
es.index(index="my-index", doc_type="test-type", id=1, body={"key": "value1"})
get(): ドキュメントを取得する
このようにインデックス、タイプ、idを指定することで登録済みのドキュメントを取得できます。
es.get(index="my-index", doc_type="test-type",id=1
以下のような辞書が返ってきます。
{'_id': '1',
'_index': 'my-index',
'_source': {'key': 'value1'},
'_type': 'test-type',
'_version': 1,
'found': True}
search(): ドキュメントの検索
適当にドキュメントを三つくらい追加しておきます。
es.index(index="my-index", doc_type="test-type", id=1, body={"key": "value1"})
es.index(index="my-index", doc_type="test-type", id=2, body={"key": "value2"})
es.index(index="my-index", doc_type="test-type", id=3, body={"key": "value3"})
検索するためにはインデックスとクエリを指定します。
クエリにmatch_allとすれば全件取得できます。
es.search(index="my-index", body={"query": {"match_all": {}}})
{'_shards': {'failed': 0, 'skipped': 0, 'successful': 5, 'total': 5},
'hits': {'hits': [{'_id': '7f6GP2ABosfH4dF68C99',
'_index': 'my-index',
'_score': 1.0,
'_source': {'key': 'value'},
'_type': 'test-type'},
{'_id': '42',
'_index': 'my-index',
'_score': 1.0,
'_source': {'any': 'data'},
'_type': 'test-type'},
{'_id': '7v6HP2ABosfH4dF6qy_0',
'_index': 'my-index',
'_score': 1.0,
'_source': {'key': 'value'},
'_type': 'test-type'},
{'_id': '2',
'_index': 'my-index',
'_score': 1.0,
'_source': {'key': 'value2'},
'_type': 'test-type'},
{'_id': '7P6CP2ABosfH4dF6PS98',
'_index': 'my-index',
'_score': 1.0,
'_source': {'key': 'value'},
'_type': 'test-type'},
{'_id': '1',
'_index': 'my-index',
'_score': 1.0,
'_source': {'key': 'value1'},
'_type': 'test-type'},
{'_id': '3',
'_index': 'my-index',
'_score': 1.0,
'_source': {'key': 'value3'},
'_type': 'test-type'}],
'max_score': 1.0,
'total': 7},
'timed_out': False,
'took': 1}
*今入力した3件以外にテストで入れたドキュメントが引っかかっています。
このように条件をつければフィルターをかけることができます。
es.search(index="my-index", body={"query": {"match": {"key":"value1"}}})
{'_shards': {'failed': 0, 'skipped': 0, 'successful': 5, 'total': 5},
'hits': {'hits': [{'_id': '1',
'_index': 'my-index',
'_score': 0.6931472,
'_source': {'key': 'value1'},
'_type': 'test-type'}],
'max_score': 0.6931472,
'total': 1},
'timed_out': False,
'took': 2}
次回
と本当にざっくりまとめてみました。
求めるところはEBSにデプロイしたFlaskアプリケーション内の検索窓にオートコンプリートを実装することです。
今回はローカルで動かしてみましたが、EBSとの連携はどうするのか、オートコンプリートをどう実装するのか(Ajax?)などなど課題はつきませんが、一歩ずつ解決していきたいです。