k近傍法 -入門 Kaggle Titanicで試してみる-
k近傍法(ケイきんぼうほう、英: k-nearest neighbor algorithm, k-NN)は、特徴空間における最も近い訓練例に基づいた分類の手法であり、パターン認識でよく使われる。最近傍探索問題の一つ。k近傍法は、インスタンスに基づく学習の一種であり、怠惰学習 (lazy learning) の一種である。その関数は局所的な近似に過ぎず、全ての計算は分類時まで後回しにされる。また、回帰分析にも使われる。
引用: k近傍法 – Wikipedia
もっとも単純な機械学習アルゴリズムと言われるk近傍法を実装してみます。
目次
k近傍法(k-Nearest Neighbor)とは
引用: k近傍法(k-Nearest Neighbor)の理解 – OpenCV-Python Tutorials 1 documentation
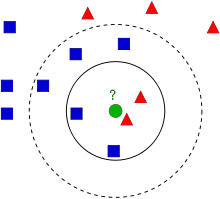
画像の引用元の説明がわかりやすかったのでここでは簡単にだけ説明します。詳しく理解したい方はリンク先をご確認ください。
図の青四角と赤三角で分類されるデータが与えられたとします。
2つの特徴量を用いて二次元に分布させると上の画像のようになりました。
この時、未知のデータ(緑丸)が青四角か赤四角かを判定します。
k近傍法では緑丸からもっとも近いk個を取得し、多数決で決定します。
例えばk=3とすると近い順に赤三角、赤三角、青四角なので緑丸は赤三角と判定。
しかしk=7とすると赤三角2つ、青四角5つで青四角と判定されます。
これが簡単なk近傍法の説明です。シンプルですね。
ちなみにkの値としてデータ数の平方根を用いると比較的うまくいくようです。
k近傍法の強みと弱み
強み
- ノイズの大きい学習データに対して有効
- 学習データが大量にある時に有効
- アルゴリズムが単純
弱み
- kの値を設定する必要がある
- どの特徴量を使うか、あるいは全ての特徴量を使うか考慮する必要がある
- 計算コストが大きい
- Kd-treeを用いることで効率化可能
- 特定のデータが多いとそれに引っ張られる
Kaggle Titanicで試してみる
Kaggle Titanicのデータセットを使って実装してみましょう。
test.csvとtrain.csvをダウンロードします。
学習データのtarin.csvをpandasで読み込んでみます。
import pandas as pd
train_data = pd.read_csv('train.csv')
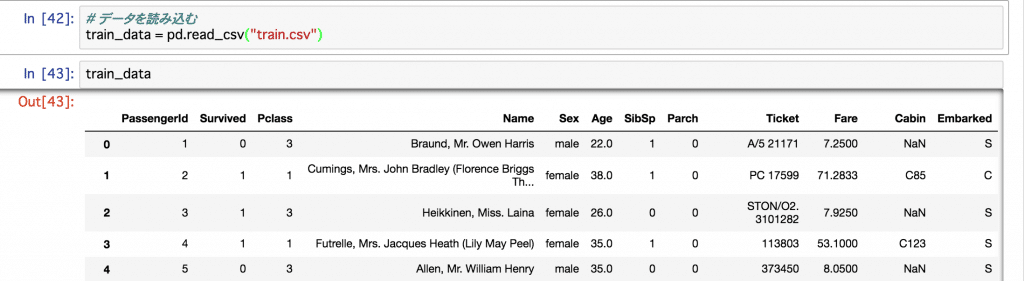
それぞれの項目は以下のことを表しているみたいです。
Survivedの値がラベル(答え)になります。
PassengerId: 乗員ID Survived: 生存判定 Pclass: 等級 Name: 氏名 Sex: 性別 Age: 年齢 SibSp: 同船した兄弟・夫婦の数 Parch: 同船した親・子供の数 Ticket: チケット番号 Fare: 料金 Cabin: 客室番号 Embarked: 乗船港
test.csvはSurvivedが抜けたデータになっています。
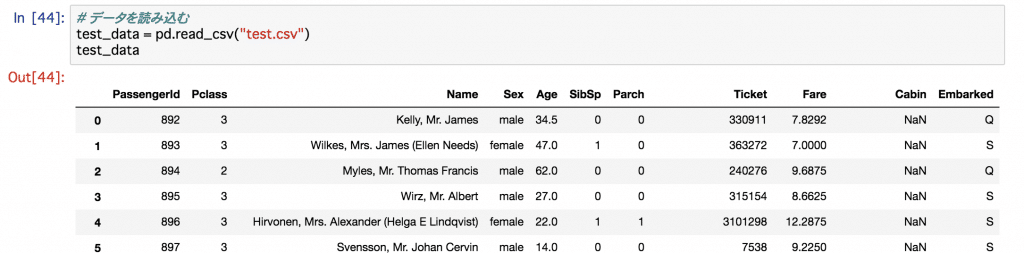
train.csvから生死とその他の項目の関連性を見つけ出し、test.csvのデータでの結果を予測せよということです。
客室の等級や性別、年齢、同船した関係者の数などは関わってきそうですね。
逆に氏名によって生存に有利というのは想像できません。
また料金は等級と乗船港に強く影響を受けそうです。項目間の関係も無視はできないですね。
まずは年齢、性別の2つの要素を使って予測してみたいと思います。
こんな感じになると予想。
性別と年齢に左右される運動能力が生死を分けるという仮説。
男性、女性共に10代後半~40代ぐらいが生存率高くて、女性の方がちょっと生存率低めになるかなと。
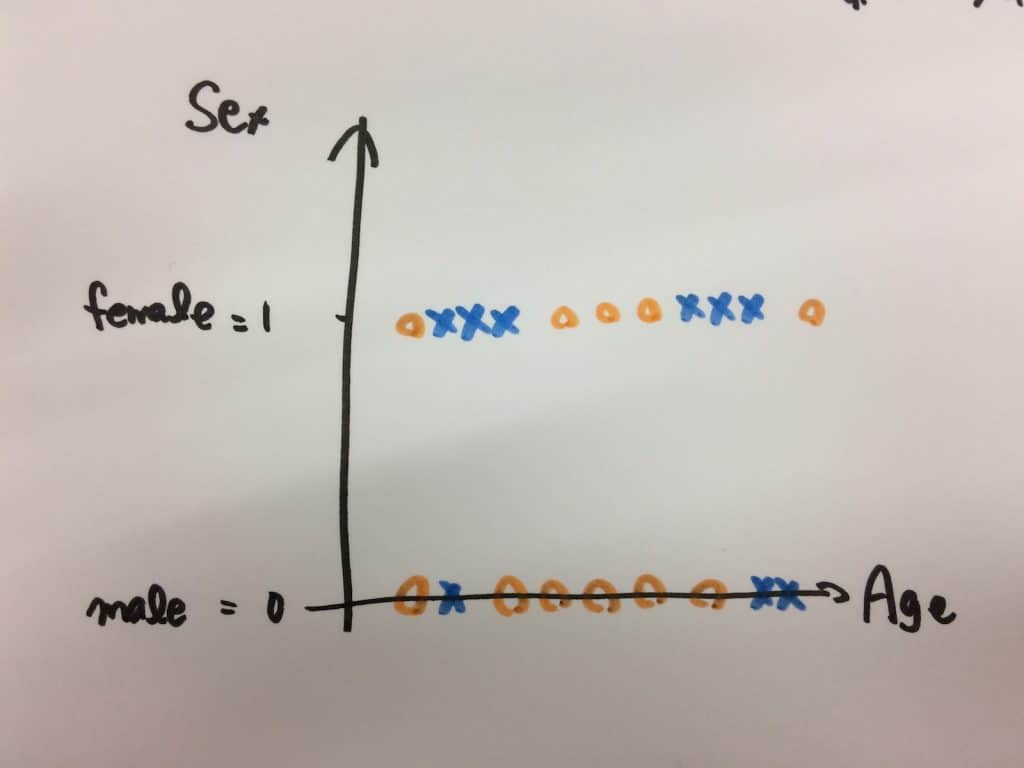
というわけで、データから生存判定、性別と年齢だけを抜き出します。
性別を数字に変換しておきます。maleを0に、femaleを1に。
さらに欠損値を除きます(平均値とかを代入すると良いかもしれません)。
train_X = train_data[['Survived', 'Sex', 'Age']].replace('male', 0).replace('female', 1).dropna()
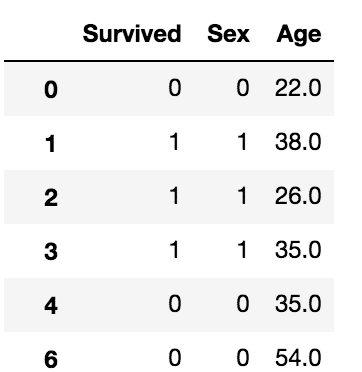
これらのデータのSexとAgeをtrain_X、Survivedをtrain_yして取得しましょう。
train_X = train_data[['Sex', 'Age']] train_y = train_data['Survived']
実行してみたらこんな感じの結果になってしまいました。
死亡が赤、生存が緑なので全て生き残るという判定になってしまいました。
(y軸の性別は0 or 1なので)
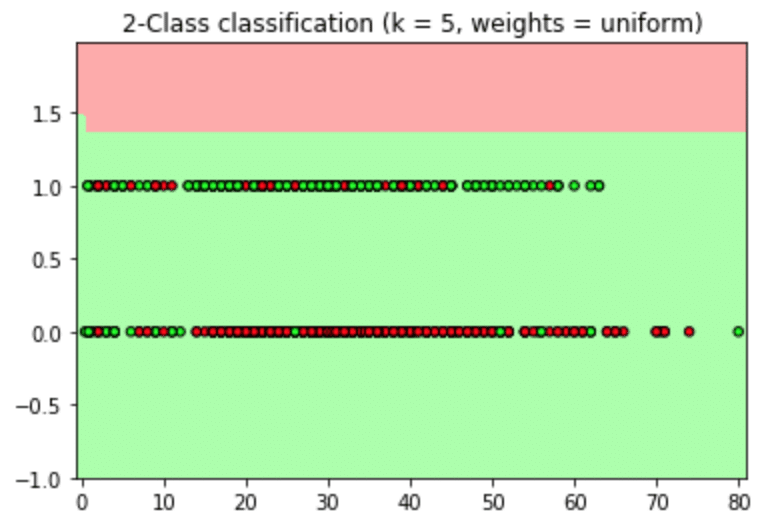
性別を使ったのがまずかったですね。
二値ではない料金(Fare)などを使ってみます。
ファーストクラスなど階級の高い人の方が助かってそうなイメージです(料金だと距離なども関わるから等級を使った方がいいとは思いますが、連続値を扱いたかった)。
ぐちゃり。
死亡が赤、生存が緑です。
プロット(実データ)では高い料金を払っている人は生存しているっぽいけど、領域的には微妙ですね。
密集しすぎているデータを使ったからでしょうか。
k = 5, 15, 30で試してみました。
それぞれ正答率は76.19%, 71.15%, 72.13%でした。
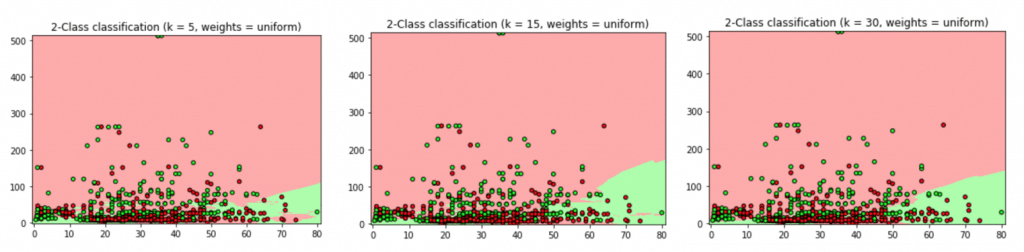
元になったデータですら75%程度。
test.csvのデータを使ってチェックしたら、k = 30がもっとも良い結果で59.33%でした。
ほぼ勘ですね。

9639人中9437でした。
ひょー。世の中舐めたらあかんと教えてくれる。
改善するには
とりあえずやってみたら微妙な結果でした。
結果を改善する方法としてここら辺を挙げてみます。
- k値を変える
- パラメータを変える、増やす
- 欠損値を除外ではなく中央値や平均値などで埋める
- 標準化する
- 距離による重み付けを加える
参考: A Complete Guide to K-Nearest-Neighbors with Applications in Python and R
一晩色々試してみましたが、66.985%がベストでした。

順位でいうと9029位。ぐぬぬ。

他の人のを見てみる
Googleで「titanic knn」とでも調べるといろんなのが出てきます。
82%ぐらいがベストみたいです。だいたい200位ぐらいのスコアですね。
ここら辺見ると「等級」、「性別」、「年齢」あたりが大事なパラメータみたいです。
というかこの3つで82%予測できるらしい。ほんとかな。
極度にパラメータが最適化されすぎなのもどうかと思いますが、パラメータは多けりゃいいってもんじゃないことは勉強になります。
k近傍の仲間たち
最近傍法(Nearest Neighbour)
もっとも近いデータの属性を採用するものです。
kNNのk=1のことです。
変形k近傍法(modified kNN)
k近傍法において近いデータはより重視するような重みをつける手法です。
例えばk=5で、とても近い位置に2つ、遠い位置に3つあった場合、近い位置のデータを重視するということです。
scikit-learnのKNeighborsClassifier()ではweightsとして'distance'を指定すると距離に応じて重みできます。
Kaggle Titanicで上を目指す
他のアルゴリズムを一通り勉強・実装してみたら次は良い結果を出せるように頑張ってみます。
自分でkNN書いてみる
TODO: そのうち気が向いたら。
おまけ
当たり前ですが、
なんとなく読んで知っているのと実装してみること、
とりあえず動かすことと使える精度まで高めることは全然違うなと思いました。まる。
初Kaggleでしたが悔しい半分、面白い半分でした。
今後もいろんなアルゴリズム勉強するときにKaggleの問題を使えば大体どれくらいの位置かわかっていいモチベになりそうです。
参考
- A Complete Guide to K-Nearest-Neighbors with Applications in Python and R
- k近傍法(k-Nearest Neighbor)の理解 – OpenCV-Python Tutorials 1 documentation
- K Nearest Neighbors Tutorial: Strength and Weakness
- 機械学習_k近傍法_理論編 | Developers.IO
- k近傍法とk平均法の違いと詳細. – Qiita
- kd-treeを実装してみた – おぺんcv
- scikit.learn手法徹底比較! K近傍法編 – Risky Dune
- Kaggleのtitanic問題で上位10%に入るまでのデータ解析と所感 – mirandora.commirandora.com
- 【教師あり学習】怠惰で強力なアルゴリズム!?k-NN【分類】 – Aidemy Tech Blog
- scikit learnより k近傍法をpythonで実装 – Qiita
- Nearest Neighbors Classification – scikit-learn 0.19.1 documentation
- KaggleチュートリアルTitanicで上位3%以内に入るには。(0.82297) – IMACEL Academy -人工知能・画像解析の技術応用に向けて-|LPixel(エルピクセル)
- K近傍法(多クラス分類) – Qiita