PyTorch DL for NLP -Bi-LSTM CRF-
前回はLSTMを使ってPOS tagging(品詞タグ付け)を行いました。
今回は応用編として、bidirectional LSTMとCRFを組み合わせたモデルを使ってNERを行います。
PyTorch公式チュートリアルの以下のページに沿って進めます。コードは以下のページからダウンロードしたものを一部改変して使っています。
目次
環境
- MacBook Pro (Retina, 15-inch, Mid 2015)
- macOS High Sierra 10.13.5
- Python 3.6.3
- PyTorch 0.4.0
Named Entity Recognition: NER
固有表現抽出と訳されます。
固有表現とは人名や地名などの固有名詞、日時や数量などの数的表現のことです。
NERで使われるタグは2つの要素からなります。
IOBフォーマット: 始まり(Beginning)、中間(Inside)、外部(Outside)を表現
NEタイプ: 組織名(ORG)、人名(PER)、地名(LOC)など
例えば以下の文は、
- John lives in New York
このようにタグづけされます。
- B-PER, O, O, B-LOC, I-LOC
Johnは人名かつ固有表現の始まりなのでB-PER、
livesとinは固有表現ではないのでO、
Newは「New York」という固有表現の始まりなのでB-LOC、
Yorkは先のNewの続きなのでI-LOCです。
NERではハードルとなる点がいくつかあります。
- 同音異義語: Onというベトナムの地名と前置詞を見分けなくてはいけない
- NE同士の曖昧性: Mayは日付にも人名にもなり得る
- 複数単語: Stanford Universityは単語の始まりと終わりを見つけなくてはいけない
NERやNEについて詳しくは以下の書籍などを参照ください。
英語版はウェブにて無料で公開されているのでこちらをご覧になるのも良いでしょう。
Long-Short Term Memory Netoworks: LSTM
LSTMについては前回触れたので深くは解説しません。
端的に表現すると、RNNの一種です。
それまでのRNNで課題だった長期記憶のメカニズムを実現したモデルです。
模式図は以下のようになります。
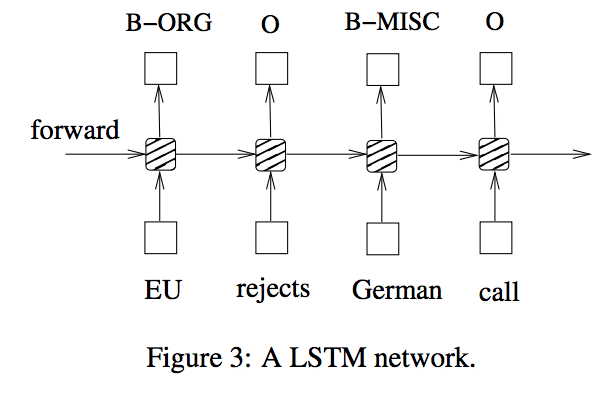
編みかけの部分の内部でLSTMに特徴的な計算を行なっているのですが、ここでは紹介を省きます。
詳しくは前回の記事をご覧ください。
Bidirectional LSTM: bi-LSTM
bidirectional LSTMではその名の通り、双方向性のLSTMです。
上記のLSTMと合わせて、系列データを反対の順から流すLSTMを用います。
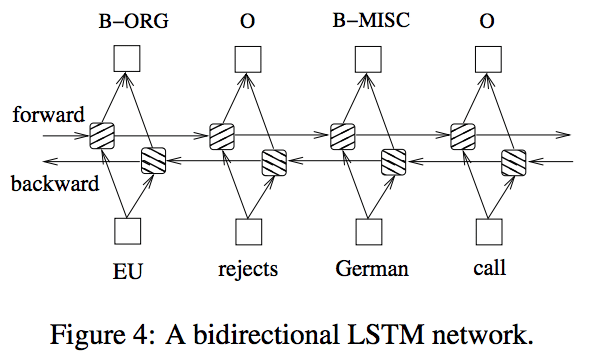
これにより、LSTMを上回る精度の分析ができます。
例えば以下のような文で考えます。
- I sleep at 10 PM.
LSTMではatの後ろに数字が来ていることから、この数字は時間を表していると判断します。
bi-LSTMではそれに加えて、その数字の後ろにPMがあることからより確信を持って時間を表していると判断ができるのです。
単純に考えて(本当に単純に考えて)判断材料が2倍になるということです。
Conditional Random Field: CRF
条件付き確率場と訳します。
言語学習のための機械学習入門では「対数線形モデルを系列ラベリング問題に適用したもの」というように定義しています。
先述のLSTMやbi-LSTMはPOS taggingで優れた結果を出しました。
しかし、出力されるラベルに依存性があるような問題では難が残ります。
例えばNERではB-PERの後には以下の3通りしか現れません
- I-PER: 人名が続く場合
- B-XXX: 他の固有表現が始まる場合
- O: 固有表現以外が出現する場合
B-PERの後にはI-LOCやI-ORGが来ては行けないという強い制約があるのです。
そこで、bi-LSTMの出力をCRFに入力し、CRFが最終的な出力(ラベル)を計算するという手法が考案されました。
これによってNERを高い精度で実行できるようになりました。
今回のLSTMに続くCRFでの処理を例に取ってCRFの働きを確認します。
CRFでは以下のような系列データX(今回の例ではxiは文章の各単語に対するLSTMの出力)が与えられます。
![]()
予測されるラベルを以下のようなyと定義します。
![]()
この時、スコアs(X, y)は以下のように定義されます。
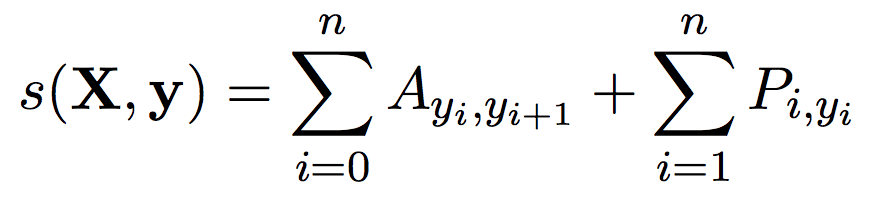
ここでAはタグの遷移スコアです。![]() はi番目のタグからj番目のタグへ遷移する時のスコアを表します。
はi番目のタグからj番目のタグへ遷移する時のスコアを表します。
またy0とynはそれぞれSTARTタグ、STOPタグと特別なタグが割り振られます。
AはNEタグ(k個)にこの2つのタグを含めた(k+2)×(k+2)の正方行列になります。
一方PはLSTMの出力をまとめたものになります。
ある単語の分散表現がLSTMに入力されると、k個のタグに対するスコアすなわち要素k個のベクトルが出力されます。
文章にはn個の単語が含まれているので、すべての出力をまとめたPはn×kの行列になります。
改めてs(X, y)を見てみます。
第一項はLSTMの出力したyの遷移に関するスコア(CRFが担保するタグのつながりの正しさ)、
第二項はLSTMによるyのスコア(LSTMが担保する各単語のタグの正しさ)であることがわかります。
つまり、LSTMにとって確信度の高い予測yであっても、CRFにとってあり得ないタグの遷移であればスコアは下がるというわけです。
CRFは対数線形モデルなので、条件付き確率p(y|X)は前述のスコアs(X, y)を用いて以下のように表現できます。
Yxは出力yが取り得るすべてのパターン(IOBフォーマットにそぐわないものも含めて)です。従って、分母はp(y|X)を0から1の範囲に収めるためのものです。
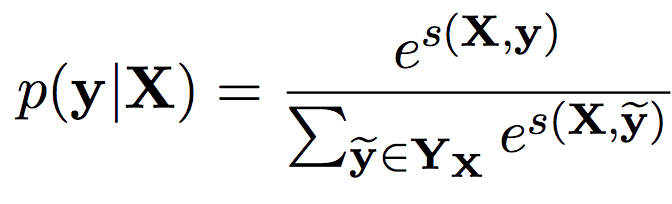
学習過程では上記確率の対数、以下のlog(p(y|X))を最大化させるようネットワークのパラメータを更新します。
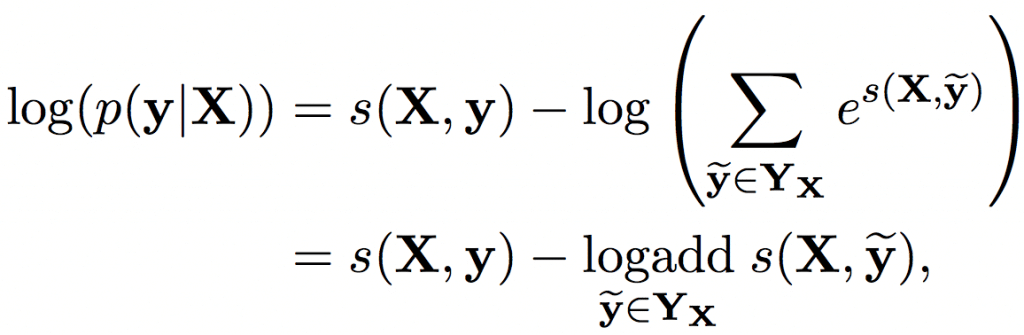
そして学習したネットワークを用いて予測をするときは、スコアを最大化するyを選択します。
なお、このときyの組み合わせはn個の単語とk個のラベルがあれば(k+2)^nと計算量が大きいのですが、後述のヴィタビアルゴリズムを導入することで計算の効率化を実現しています。
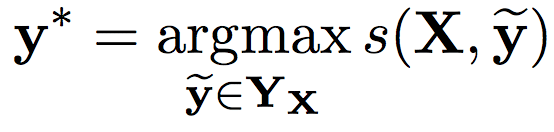
bi-LSTM CRF実装
模式図は以下のようになります。bi-LSTMの出力をCRFに投入して、文章内の単語に対するNERを行います。
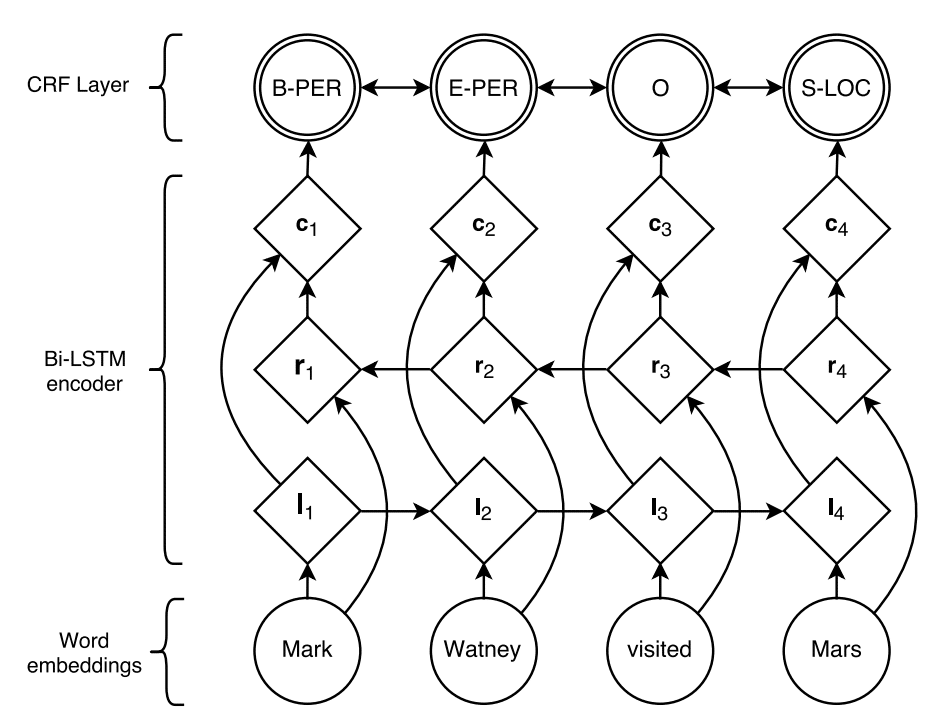
これによって高い精度でNERができる、とのことです。
詳しくは画像の引用元の論文を参照してみてください。
(ただし論文ではcharacterレベルの情報も用いています。以下で紹介するPyTorchのbi-LSTM CRFモデルはwordレベルなので注意)
では実際に公式チュートリアルのコードを紐解いてみます。
まずは諸々インポート。
後々使う便利関数を設定しておきます。
まずはベクトルの最大要素のindexを返すargmax()。
系列データをインデックのリストに変換するprepare_sequence()。
log_sum_exp()
モデルの実装部分です。ひとまずメソッド名だけ見ます。
かなり長いですが、これは損失関数をクラスの中で定義していることが理由の一つです。
一つずつ確認します。
まずはコンストラクタ__init__()です。
次に_forward_alg()です。これは損失関数の計算に使われます。
小さい方が好ましいです。
ここで使われてる関数については以下に補足します。
- torch.full(): 第一引数の形のtensorのすべての要素に第二引数の値を代入
- torch.Tensor.expand(): 引数の形式に引き伸ばす
- torch.cat(): 与えられたシーケンスを繋げる、第二引数は軸の指定
_get_lstm_features()はforward()でLSTMの部分の計算として実行されます。
前回実装したLSTMの出力を取得します。
_score_sentence()はs(X, y)を計算します。
_viterbi_decode()はLSTMの出力を受け入れ、それから入力文章に対応するNEタグのリストを予測します。
これと合わせて出力NEタグのスコアを算出します。
n個の単語がそれぞれk個のタグをとり得るので場合の数はk^nとなりますが、ヴィタビアルゴリズムで計算することにより効率的に計算しています。
neg_log_likelihood()は_forward_alg()と_score_sentence()の返り値の差で表されます。
損失関数なので当然小さい方が好ましいです。
最後にforward()について見ます。
まず_get_lstm_features()で入力した系列データに対するLSTMの出力を得ます。
これを_viterbi_decode()に渡し、予測した出力tag_seq(論文のy)とそのスコアを得ます(論文のs(X, y))。
いよいよ学習の部分です。
以上でbidirectional LSTMとCRFを組み合わせたNERが実装できました。
ちゃんとしたデータセットで検証してみます。
character-based word representations
以上、PyTorch公式で紹介されているbidirectional LSTM CRMモデルを雑に開設しました。
ところでbidirectional LSTM CRFモデルを用いたNER(Lample, 2016)ではcharacterレベルの情報が用いられていました。
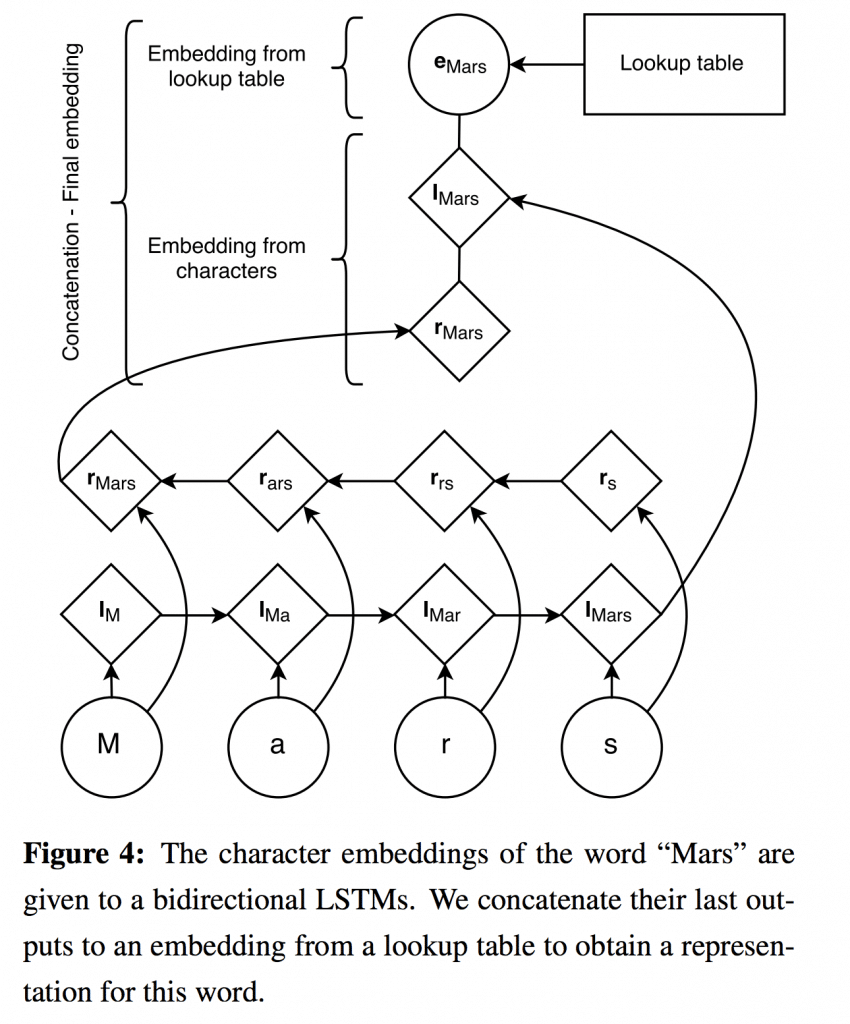
簡単にいうと、各単語を文字単位のLSTMに突っ込んでその出力を通常の単語ベクトルにconcatするというアイディアです。
つまり元のモデルを細かく表示するとこんな感じ。
単語Marsについて考えると、まず”M”, “a”, “r”, “s”を文字レベルのLSTMに突っ込んで出力を得ます(両方向なのでlmars, rmars)。これらがそれぞれ25次元。
事前学習済みの単語ベクトルからMarsの単語ベクトルを取得します(emars)。これが100次元。
100 + 25 + 25でconcatして150次元。これを単語レベルLSTMの入力に使う単語ベクトルとします(事前学習済みの単語ベクトルに文字レベルの情報を付与したと言える)。
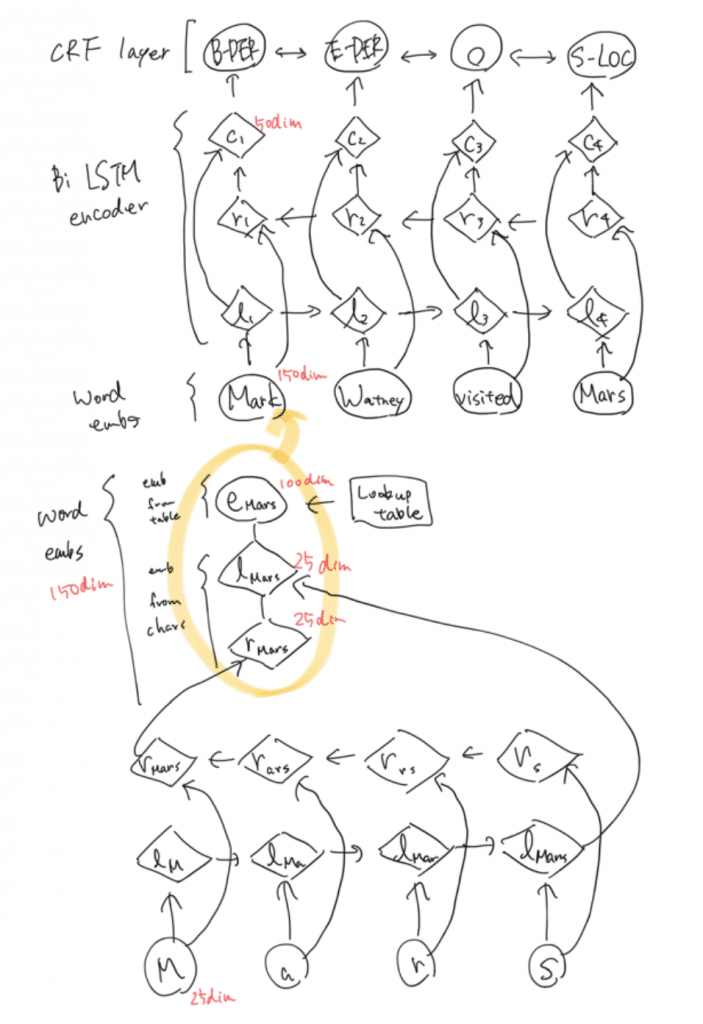
文字レベルの情報を考慮することにより、prefixやsuffix、つまり単語の先頭や末尾の情報をバッチリ考慮できます。
これがPoS taggingやNERによく効くのは感覚的にわかるでしょう。
簡単な実験をしてみました。
文字レベルのLSTMを追加することでどれだけ精度が変わるか。
- タスク: PoS tagging
- データセット: Penn Treebank
- train: 2739 sentences
- test: 1175 sentences
- モデル:
- 単語レベルLSTM①
- word emb dim: 100
- 単語レベルLSTM②
- word emb dim: 125
- 単語レベルLSTM + 文字レベルLSTM
- word emb dim: 100
- char emb dim: 25
- 単語レベルLSTM①
- エポック数: 10
- 計算環境: AWS EC2 p2.xlarge
| 単語① | 単語② | 単語 + 文字 | |
| Accuracy | 82.22% | 81.82% | 92.52% |
| Time | 3min 27s | 5min 24s | 18min 11s |
こんな感じ。
word embの次元数を増やしても対して性能上がらないけど(ていうか下がってる)、文字レベルの情報を入れることでかなり精度が上がりました。
単方向のLSTMなのでbidirectionalにしてCRF乗っけたらもっと良くなりそう。
ちなみにPoS taggingのstate of the artは98%弱。
コードは以下に置きました。適当に試してみてください。
しかし、GPU利用にしているはずなのに手元のMacと計算時間が変わらない。
多分、LSTMの系列長が可変だからうまいことGPU利用できてない?
pack_padded_sequence()で系列長揃えると早くなるんだっけ?そこらへん勉強不足です。。。
参考
- Advanced: Making Dynamic Decisions and the Bi-LSTM CRF — PyTorch Tutorials 0.4.0 documentation
- 7. Extracting Information from Text
- わかるLSTM ~ 最近の動向と共に – Qiita
- Bidirectional LSTM-CRF Models for Sequence Tagging
- Neural Architectures for Named Entity Recognition
- CRFがよくわからなくてお腹が痛くなってしまう人のための30分でわかるCRFのはなし – EchizenBlog-Zwei
- Named Entity Recognition Tagging
- 言語処理における識別モデルの発展 – HMMから CRFまで(pdfがダウンロードされます)

言語処理のための機械学習入門 (自然言語処理シリーズ) Posted with Amakuri at 2018.6.12 高村 大也 コロナ社 Amazonで詳細を見る

入門 自然言語処理 Posted with Amakuri at 2018.6.8 Steven Bird, Ewan Klein, Edward Loper オライリージャパン Amazonで詳細を見る