Python メモリに乗らない巨大なデータを扱う
データ分析をする際、CSVなりJSONなりXMLなりファイルからデータを読み込みます。
ここではメモリに展開できないような巨大なファイルを扱う際の手法をまとめます。
消費メモリの確認には以前紹介したmemory_profilerを使っています。
目次
XML
おさらい: PythonでXMLファイルを読み込む
Pythonでは標準ライブラリのxml.etree.ElementTreeを使ってXMLファイルを扱うことができます。
ファイルパスを使って読み込む場合はこのように。
import xml.etree.ElementTree as ET ET.parse(file_path)
stringを直接扱う場合は以下のようにします。
ET.formatstring(data)
これでPythonでXML形式のデータを扱うことができます。
しかし、巨大なXMLファイルを読み込むとメモリに乗せきる事が出来ずエラーが発生します。
今回はメモリに乗り切らない巨大なXMLファイルをPythonで扱う方法についてまとめました。
方法1: ElementTreeのiterparse()でストリーミング処理する
そこでXMLファイルを一気にメモリに読み込むのではなく、逐次的に読み込む方法を使います。
iterparse()メソッドを用います。
iterparse(source, events=None, parser=None)
引数は、sourceにファイルパスを指定。
eventsはstartを指定すれば開きタグをトリガーに、endを指定すれば閉じタグをトリガーにiterationが回ります。
省略した場合、endが使われます。これを使いタグごとに読み込むことでメモリを節約できます。
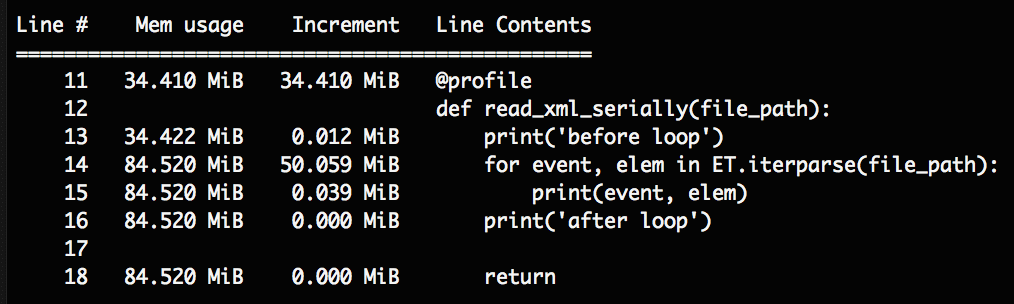
ではiterparse()を使って逐次読み込みをしてみましょう。
forループの中で逐一メモリを解放してあげます。
import memory_profiler
import xml.etree.ElementTree as ET
@profile
def read_xml_serially(file_path):
for event, elem in ET.iterparse(file_path):
print(event, elem)
elem.clear()
return
if __name__=='__main__':
file_path = 'test.xml'
read_xml_serially(file_path)
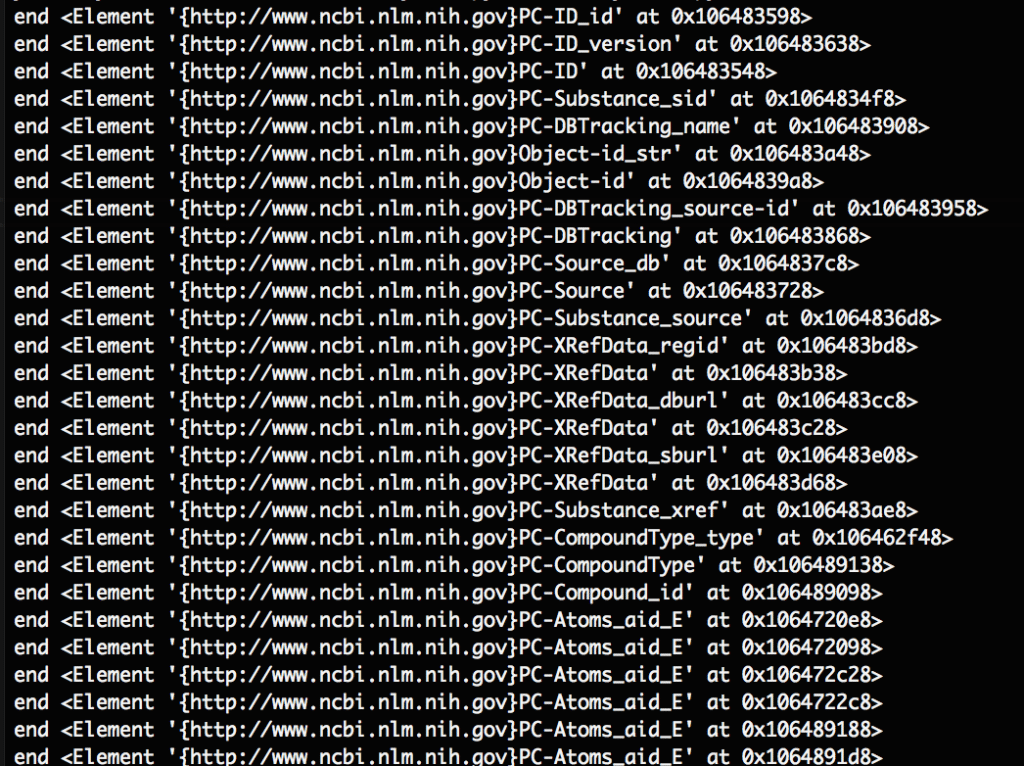
出力はこんな感じ。オプション引数のeventsを指定しないとこのようにendのタイミングで取得します。
内容が取りたい場合はこれで良いと思います。
ちなみに元々のファイルはこんな感じです。
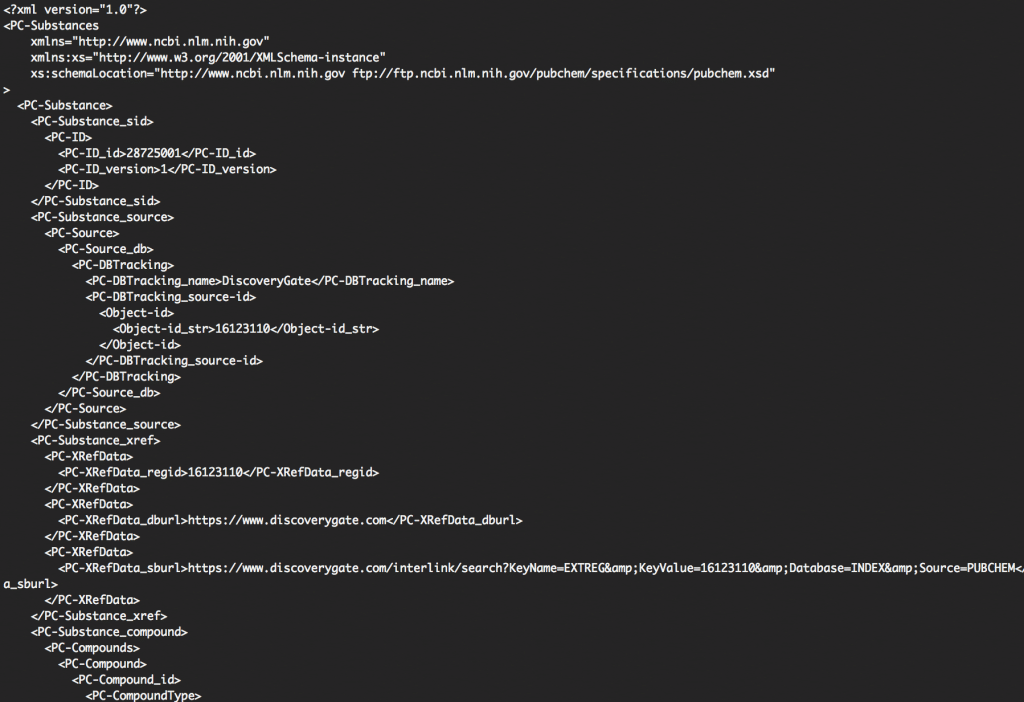
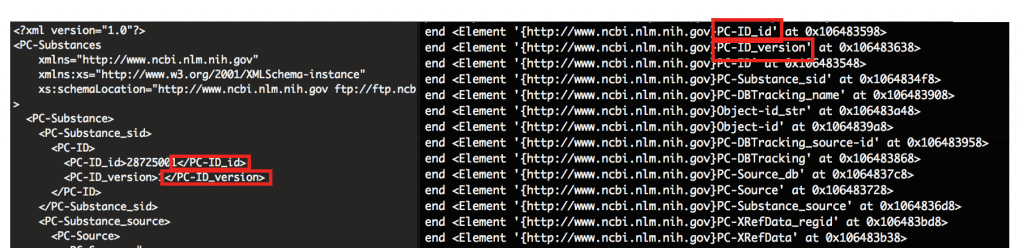
見比べると閉じタグが出現する順番に該当の要素を読み込んでいることがわかります。
プログラム実行中のメモリを見てみると。。。
(参考: Python memory_profilerで実行中のメモリ消費量を確認する)
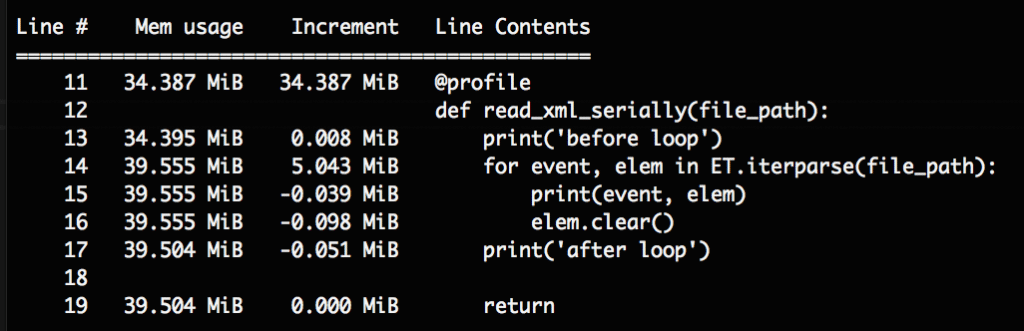
比較してみましょう。
parse()で一気に読み込んだ場合です。85MiBほどメモリを消費していることがわかります。
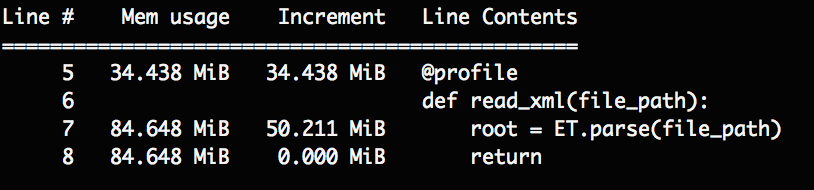
またelem.clear()しなかった場合もメモリに残り続けます。
この場合も同様に85MiB使っていることがわかりました。
使わない変数はメモリから解放するようにしましょう。
調べてみると、こんな記事が見つかりました。
この方法だと一つ欠点があり、forループの最後に読み込むのendイベントがrootの閉じタグになります。
するとこのrootの中にはそれまでclear()した大量の空の子要素が含まれることになるらしいです。
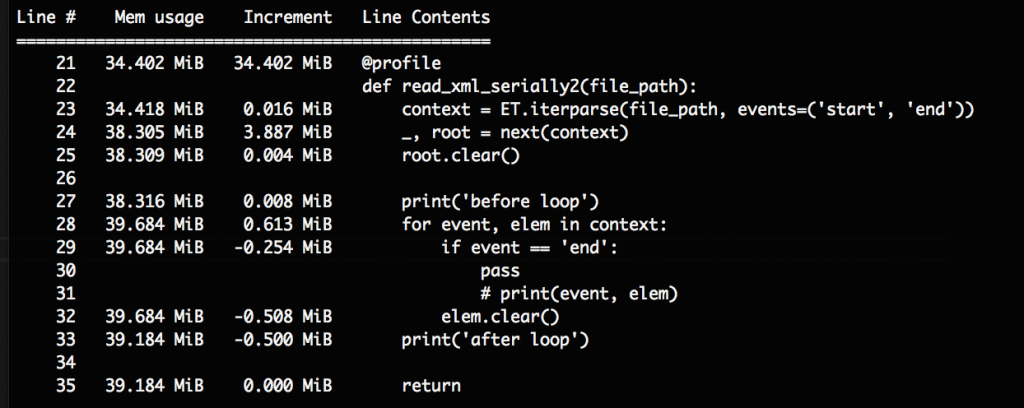
子要素が極めて大量な場合にはバカにならないので、以下のようにあらかじめrootを削除しておくことが推奨されていました。
(以下のroot.clear()はelem.clear()のタイポかと思いますが、どうでしょうか詳しい人こちらにコメントください)
2018/02/02 編集
この件に関して@shuntaroy様に質問したところ回答をいただきました。
前述のように、rootの中に空のElementが大量に残ってしまい、大容量のXMLファイルなどではそれが無視できないほどメモリを圧迫するそうです。したがってroot.clear()で消す必要があるとのことでした。

引用元: The ElementTree iterparse – Function
今回読み込んだのは4MB程度のXMLファイルだったのであまり変化はありませんでしたが。覚えておきましょう。
方法2: SAXを使う
後日まとめます。
方法3: lxmlを使う
後日まとめます。
http://lxml.de/
JSON
Don’t use humongous json files, ever!
redditでも馬鹿でかいJSONファイル使うなと書いてありました。
方法1: ijsonでストリーミング処理する
XMLで言うところのElementTreeのiterparse()のようです。
数GBものJSONをロードしようとすればフリーズ必至なので、ijsonで頭から逐次的に処理していきます。
方法2: 小さいファイルに分割する
mongodb
おまけ
CSV、JSONなども後ほど追加します。
参考
XML
- 20.5. xml.etree.ElementTree — ElementTree XML API Python 3.6.3 ドキュメント
- Parsing Large XML files, Serially, in Python
- The ElementTree iterparse – Function
- PythonとSAXでXMLを扱う – shogo82148’s blog
- 第5回・XMLファイル|CSV、XML、JSON…データフォーマットの変遷について考える | GiXo Ltd.
- Convert XML structure into a Pandas DataFrame – Austin Taylor
- 数GB以上の巨大なXMLをPythonで読むときのメモリ節約法 – Qiita
CSV
- pandas.DataFrame – pandas 0.22.0 documentation
- pandas でメモリに乗らない 大容量ファイルを上手に扱う – StatsFragments
- Pandas.DataFrameのメモリサイズを削減する(最大で8分の1) [Python] – Qiita