SummerEye part7 -高速化-
さすがに1ファイル5秒かかるようでは大量のファイルを扱えない。
それじゃ使い勝手が悪い。
せめてプログレスバーは表示させたいです。
目次
時間計測
205KBの猫ちゃん画像一枚でこんな感じです。
start upload_to_BLOB: 0.0042650699615478516sec end upload_to_BLOB: 0.5201702117919922sec start save_file: 0.520233154296875sec end save_file: 0.6028749942779541sec start get_description: 0.6029150485992432sec end get_description: 4.062183141708374sec description: a-cat-that-is-looking-at-the-camera start create_zip: 4.062453031539917sec end create_zip: 4.063966989517212sec
案の定というかComputer Vision APIを叩くとこに時間がかかっています。
ここだけで3.4secぐらい。
ここはもう画像サイズに依存する通信速度というよりは、APIサーバ内での分類に時間がかかってるんじゃないかなと予想。
つまりこっち側でできることはないのでは?
(後述しますが、できることたくさんありました)
BLOBを使わない
現在、APIを叩く時 BLOBのURLを使っているんですが、サーバ内のパス指定でやったらどうなるか検証します。
start upload_to_BLOB: 0.0044820308685302734sec end upload_to_BLOB: 0.21289300918579102sec start save_file: 0.2129528522491455sec end save_file: 0.32558703422546387sec start get_description: 0.32562994956970215sec end get_description: 3.256577968597412sec start create_zip: 3.2568159103393555sec end create_zip: 3.258357048034668sec
ちょっと良くなった?get_descriptionで2.9secぐらい。
こうなるともはやBLOBに保存することは不要。。。
BLOB保存を抜いてみる。
これで0.2secぐらい早くなるはず。
start save_file: 0.003812074661254883 sec end save_file: 0.00434112548828125 sec start get_description: 0.004353046417236328 sec end get_description: 3.1944820880889893 sec start create_zip: 3.195725202560425 sec end create_zip: 3.2059221267700195 sec
全体としてあまり変わらず。
多分API側の速度にムラがあるんだろうなぁ。
結局ディスクリプションの取得に3secくらいかかるか。
ファイルサイズでの速度比較
重いファイルでも比較。
150KBの画像で3.1sec、
1.4MBの画像で3.8sec。
画像の重さでも結構変わります。
保存後、APIを叩く前に軽くするとか?
ネコ、イヌ、レッサーパンダの3枚の画像をあげてみると9secぐらいかかってしまいました。
うーん。なんだかなぁ。
grequestsを使ってHTTPリクエストを非同期処理
非同期処理的にHTTPリクエストを行える便利なライブラリがあるとのことです。
とりあえず入れてみる。
pip install grequests
使い方にちょっと戸惑いながらもこんな感じで実装。
(paramsとかは事前に定義済みです)
def get_description_list(paths):
description_list = []
url = "http://westcentralus.api.cognitive.microsoft.com/vision/v1.0/analyze?%s" % params
headers = {
'Content-Type': 'application/octet-stream',
'Ocp-Apim-Subscription-Key': subscription_key,
}
res = (grequests.post(url, headers=headers, data=open(p, 'rb').read()) for p in paths)
res_list = grequests.map(res)
for r in res_list:
parsed = json.loads(r.text)
description = parsed["description"]["captions"][0]["text"].replace(" ", "-")
description_list.append(description)
return description_list
150KB、200KB、800KBの3ファイルを投げてみる。
start get_descriptions: 0.03051304817199707 sec end get_descriptions: 3.2018191814422607 sec start create_zip: 3.2022221088409424 sec end create_zip: 3.2059621810913086 sec
早い!9secぐらいだったのがほぼ1ファイルの時と変わらない3secになりました!
試しに10ファイル投げてみる。
こんな感じのファイルを投下。
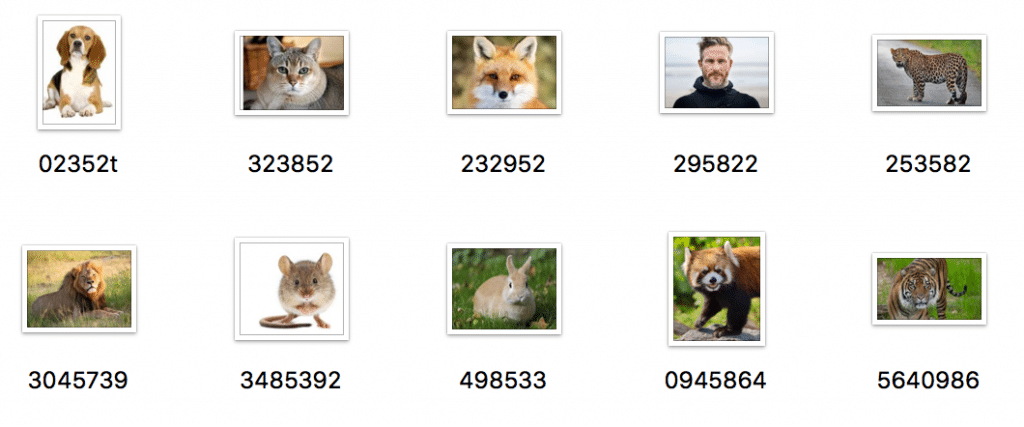
start get_descriptions: 0.06829094886779785 sec end get_descriptions: 3.9539849758148193 sec
10ファイルで4sec弱!これなら十分使えそうです。
気になる精度は、
いい感じです。

レッサーパンダが「panda-bear」、ネズミが「rodent」、ウサギが「small-animal」なところがもう少し細かく分類できるといいなと思いますが。
他はちゃんと動物の名前取れているので検索の役に立ちそうです!
デモ動画
並列処理
今回実装には至りませんでしたが、multiprocessingやJoblibを使うとさらに並列処理を行うことができるようです。
ちなみに今使っているApp ServiceのF1インスタンスのコア数は「Shared(60 CPU 分/日)」と書いてあります。
よくわからない。
コア数の多いインスタンスに切り替えられたら実装しようと思います。
クアッドコアなら最高4分の1になる可能性がありますし。
現段階10ファイル4secなので、40ファイルが4sec、100ファイル10secで処理できると期待できます。
なかなか実用的ではないでしょうか。
次回
デザインも何もない状態なので、ある程度整えます。
参考
- 【Python】処理にかかる時間を計測して表示 – Qiita
- http – How to send zip files in the python Flask framework? – Stack Overflow
- kennethreitz/grequests | Github
- Post JSON using Python Requests – Stack Overflow
- Quickstart | Requests 2.18.4 documentation
- python の map オブジェクトを list にした後は何も残らない – Qiita
- Python requests with multithreading – Stack Overflow
- Python並列処理(multiprocessingとJoblib) – Qiita
- Python の zip( ) は、3つ以上のシーケンス・オブジェクトでも、同時にループできる ~4つまでテストして、成功した件 – Qiita
- Post JSON using Python Requests – Stack Overflow
- asynchronous – Python grequests with custom header – Stack Overflow