AWS Amazon DynamoDB -入門 jsonファイルからデータロード-
前回はDynamoDBにテーブルを作成して、手動で項目を追加しました。
今回は、jsonファイルからデータを読み込ませ項目をロードします。
以下の公式ページを参考にしました。
AWS-CLIを用いたものと、Python boto3を用いたものを紹介します。
目次
AWS-CLIを使ってデータをロードする
テーブルの作成
AWSのサンプルデータを用いるのでそれに合わせてテーブルを作成しておきます。
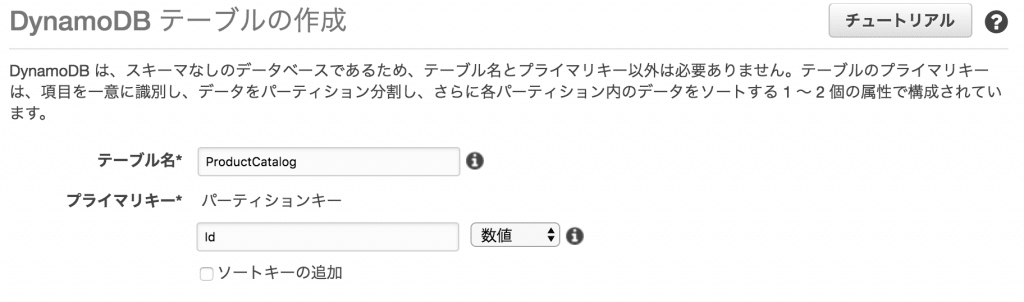
以下の設定でテーブルを作成します。
- テーブル名: ProductCatalog
- パーティションキー: Id (数値)
jsonファイルを用意
まずは以下のリンクからzipファイルをダウンロードします。
リンク切れの場合はお手数ですがAWSのチュートリアルから探してください。
展開します。ここではProductCatalog.jsonを使います。
中身はこんな感じ。

RDBMSとの大きな違いはテーブル作成時に定義していない属性(RDBMSで言う所のカラム)が用いられている点です。
プライマリーキーさえ指定してあればあとは自由な属性を使用できます。
項目ごとに属性に違いがあっても構いません。
jsonファイルを使ったデータロード
ターミナルで先ほどのProductCatalog.jsonがある場所に移動します。
AWS CLIを使用します。
ここではaws-shell経由で利用するので設定をしていない場合はこちらの記事を参考に設定してください。
以下のコマンド(batch-write-item)でファイルから項目を作成します。
$ aws-shell
aws> dynamodb batch-write-item --request-items file://ProductCatalog.json
{
"UnprocessedItems": {}
}
Python boto3を使ってデータをロードする
boto3を利用することでPythonプログラムから簡単にDyanamoDBを操作できます。
テーブルを作成
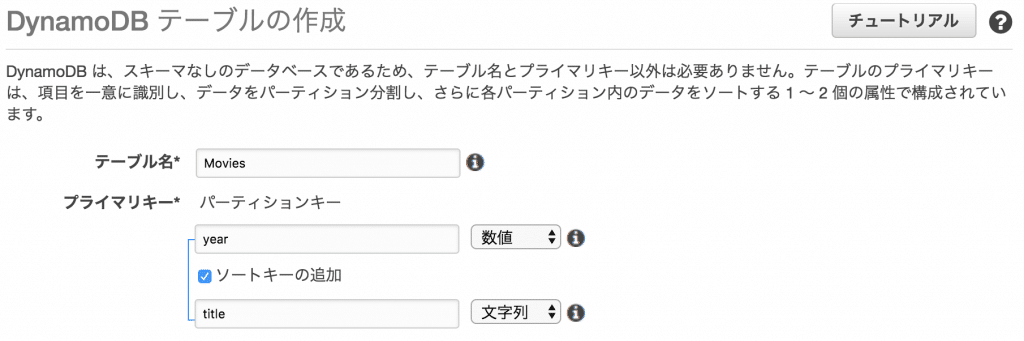
以下の設定でDynamoDBにテーブルを作成します。
- テーブル名: Movies
- パーティションキー: year (数値)
- ソートキー: title (文字列)
テーブル作成もPythonプログラムで行いたい場合はこちらをご覧下さい。
jsonファイルを用意
こちらのzipファイルをダウンロード、展開してください。
こんな感じのjsonファイル。
Pythonファイルとjsonファイルは同じディレクトリに配置しておきましょう。
jsonファイルを使ったデータロード -put_item()-
公式チュートリアルで紹介されているようにput_item()メソッドを使ってロードしてみます。
リンク先のコードをコピペし、適当にmovie.pyとでもしておきます。
python movie.py
moviedata.jsonがmovie.pyと同じディレクトリにあるか注意してください。
moviedata.jsonには4000件ぐらい入っていたので1000件に減らして実行したところ、
140秒かかりました。
ちなみに、以下のようにSession()メソッドを挟むことで任意のprofileでの実行が可能です。
from boto3.session import Session
session = Session(profile_name=PROFILE_NAME)
dynamodb = session.resource('dynamodb')
jsonファイルを使ったデータロード -Batch Write-
put_item()ではfor文ごとに項目を追加していました。
Batch Writeを使ってまとめて追加するようにしてみます。
import boto3
import json
import decimal
if __name__=='__main__':
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('Movies')
with open("moviedata.json") as json_file:
movies = json.load(json_file, parse_float = decimal.Decimal)
with table.batch_writer() as batch:
for movie in movies:
year = int(movie['year'])
title = movie['title']
info = movie['info']
print("Adding movie:", year, title)
batch.put_item(
Item={
'year': year,
'title': title,
'info': info,
}
)
with table.batch_writer() as batch:をfor文の前に追加し、table.put_item()をbatch.put_item()に変更するだけです。
これで140秒から6.8秒になりました。
大量の項目を追加する時はBatch Writeを使うようにしましょう。
おまけ
次回は5000万ぐらいのデータを入力してレスポンスの早さを見てみたいです。
最終的には2億くらいのデータを入力します。