SQL -インデックスの効率的な設定-
SQLのインデックスについて、「貼るとなんか早くなるやつ」っていう程度の認識しかなかったので一から勉強してみました。
普段はMySQLを使うのでここでもMySQLを想定しています。
基本的にMySQLリファレンスマニュアルおよび以下の書籍のインデックスに関する項目を参照しています。

目次
インデックスとは
一言で言えば、検索を効率化するために設定するものです。
MySQL曰く、以下の通りです。
インデックスは特定のカラム値のある行をすばやく見つけるために使用されます。インデックスがないと、MySQL は関連する行を見つけるために、先頭行から始めてテーブル全体を読み取る必要があります。テーブルが大きいほど、このコストが大きくなります。テーブルに問題のカラムのインデックスが含まれている場合、MySQL はすべてのデータを調べる必要なく、データファイルの途中のシークする位置をすばやく特定できます。これはすべての行を順次読み取るよりはるかに高速です。
引用: MySQL :: MySQL 5.6 リファレンスマニュアル :: 8.3.1 MySQL のインデックスの使用の仕組み
SQLデータベースではレコードが多くなってくると単純な検索にも時間がかかります。
これはインデックスを設定しない場合、フルテーブルスキャンが行われるからです。
つまりテーブルの内容を全て読み込んでしまうため、レコードの数に如実に影響を受けます。
インデックスを設定することで得られる恩恵として最もわかりやすいものは、WHERE句での比較が高速化することです。
たとえばcol1というカラムにインデックスを設定した場合、以下のようなcol1を検索の条件にするような検索が早くなると期待できます。
SELECT * FROM table WHERE col1 = 1;
インデックスを設定するとフルテーブルスキャンが行われず(いくつかの条件を満たす必要あり)、必要な部分だけを読み出します。これによってレコード数が増えても高いパフォーマンスを実現できます。
インデックスの効果を確認する
2つのカラム、id、nameを持つテーブルを作って検証します。
- id: INT 11
- name: VARCHARA 255
1000万件のレコードを投入しました。
レコード投入の高速化についてはこちらでまとめました。ご参考までに。
通常MySQLではテーブルにデフォルトでidカラムが設定されています。idにはPRIMARYキー(主キー)が設定されています。
すなわち、何もしなくてもWHERE句にidを使った場合は高速に結果を取得できると想像できます。
このテーブルに対してidを検索条件にした以下のクエリを実行します。
SELECT * FROM table WHERE id = 1;
3.7msでした。
一方、nameを検索条件にすると2.37sかかりました。640倍も時間がかかっています!
SELECT * FROM table WHERE name = 'name';
もし頻繁にnameを検索するようなら影響が大きいですね。
nameもインデックスに追加しましょう。
ALTER TABLE table ADD INDEX (name);
ちなみに1000万行で73.9sかかりました。
では再びnameで検索してみます。
SELECT * FROM table WHERE name = 'name';
0.4msに改善されました!
これがインデックスの効果です。
マルチカラムインデックスとは
単一のインデックスで絞りきれないような場合にはマルチカラムインデックスといって複数のカラムを対象にしたインデックスを作成できます。
カーディナリティーとは
インデックスを設定する上で理解しておくべき概念にカーディナリティというものがあります。
レコードの数に対してカラムの値の種類が少ない場合はカーディナリティが低いと表現します。
例えば、東京都民をレコードとするテーブルを考えます。
性別というカラムはmale、femaleの2種類程度であるのでカーディナリティが低いです。
一方、マイナンバーというカラムは被りがないので非常にカーディナリティが高いです。
インデックスはカーディナリティが高いものを設定するとより効果的です。
インデックスが使用されない場合
劇的な効果を発揮したインデックスですが、ここでは適用されない場合をみます。
MySQLでは以下のような時にインデックスが使用されず、フルテーブルスキャンが採用されてしまいます。
インデックスの仕組み
Bツリー索引というのを用いているらしいです。
詳細は後ほど調べて追記します。
インデックスとレコード追加の関係
インデックスが設定されているとレコードが挿入された時にインデックスの更新が起こるため、データの投入に時間がかかります。
2つのカラム、id、nameを持つテーブルを作って検証します。
- id: INT 11
- name: VARCHARA 255
1000万件のレコードを投入しました。
(LOAD DATA INFILEを使いました)
- インデックスなし: 36.8s
- インデックス1つ(id): 33.9s
- インデックス2つ(id, name): 75.8s
*MySQL 5.7.21を利用
インデックスを1つから2つに増やすと倍以上かかっています。
インデックスが増えるとレコードの追加に予想外に時間がかかるかもしれないので気をつけたいです。
ただ、同量のレコードに対してロード後にインデックスを貼る場合(インデックス1つで投入した後、nameをインデックスに追加する場合)、この条件では合計するとより時間がかかってしまうので注意です。
いずれにせよ不要なインデックスは設定しないようにということですね。
インデックス作成やデータロードの順番についてはこちらで実測値がまとめられていました。
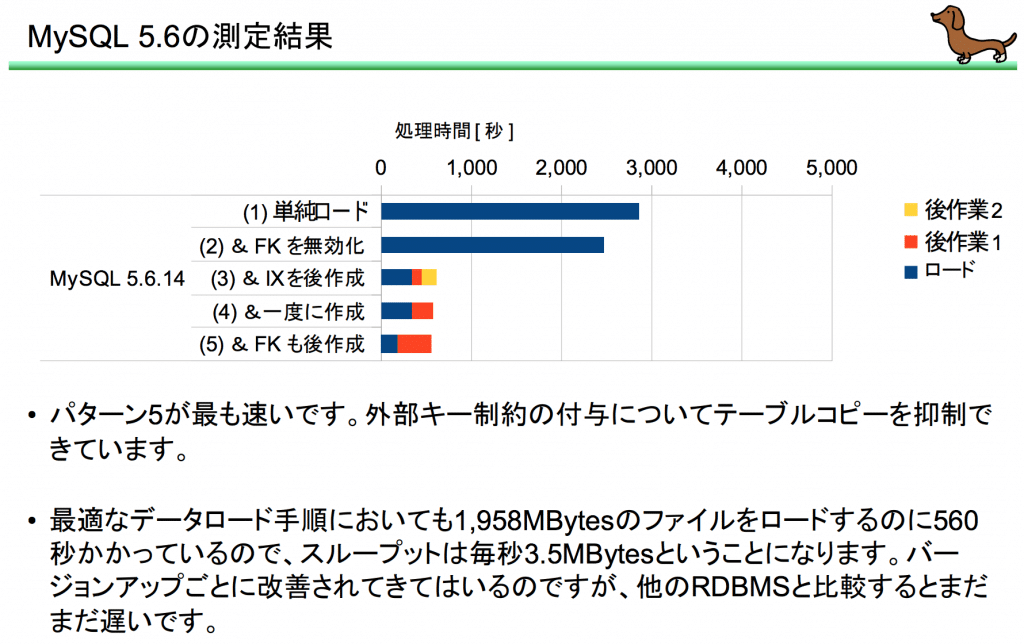
資料によると、MySQL5.6では「主キー -> データロード -> セカンダリーキー」の順序が良いみたいです。
結構変わりますね。
参考
- MySQL :: MySQL 5.6 リファレンスマニュアル :: 8.3 最適化とインデックス
- カーディナリティ – オラクル・Oracleをマスターするための基本と仕組み
- カーディナリティについてまとめてみた – Qiita
- MySQLの範囲検索でレコードが多すぎるとフルテーブルスキャンになってしまう現象 – 明日から本気だす
- MySQL 5.6における大量データロード時の考慮点
- 第6回 パフォーマンスの基礎である索引について
- インデックス範囲スキャンとフルテーブルスキャンの損益分岐点 – kagamihogeの日記
- MySQLのインデックスについて学びました – (2015年までの)odaillyjp blog