SQL -大量データ入力の高速化-
SQLにデータを投入する色々な手法とそのスピードについてまとめました。
検証にはMySQL 5.7を使用しています。
結論から言うと、設定ファイルをカスタマイズしてLOAD DATA INFILEを使うのが早いです。
目次
前提
こんな感じのusersテーブルを仮定します。
| id | name | gender |
|---|---|---|
| 1 | John | male |
| 2 | Anna | female |
PythonスクリプトからINSERT
プログラム実行中に生成したデータなどをINSERTする場合は、mysql.connectorを使うことができます。
1件~数件の入力
少ない件数のデータならこの方法で十分です。
一件の場合はシンプルにINSERTクエリをexecute()で実行します。
execute()メソッドはクエリを
import mysql.connector
data = ('Satoshi', 'male')
conn = mysql.connector.connect(user=DB_USER, password=DB_PASSWORD, host=HOST, database=DATABASE)
cur = conn.cursor()
query = "INSERT INTO users (name, gender) VALUES (%s, %s)"
cur.execute(query, data)
入力するデータは変数dataにセット型で設定してexecute()の引数に渡してあげると自動でエスケープ処理もしてくれるのでおすすめです。
(query内に直接書くとなると色々気をつけなくてはいけない)
複数件の入力
ちょっと多めのデータならこの方法。
前項のexecute()で大量のデータをINSERTするとなると効率が悪くなってしまいます。
そういう時はexecutemany()を用います。
import mysql.connector
data = [
('Satoshi', 'male'),
('Mary', 'female')
]
conn = mysql.connector.connect(user=DB_USER, password=DB_PASSWORD, host=HOST, database=DATABASE)
cur = conn.cursor()
query = "INSERT INTO users (name, gender) VALUES (%s, %s)"
cur.executemany(query, data)
dataがリスト型になっただけでexecute()をexecutemany()に変更すればそれで問題なく動きます。
これ以上の大量のデータは次項のCSVを使ったインポートをオススメします。
Sequel ProでCSVインポート
大量のデータをテーブルに挿入する場合は、まず以下のようなCSVを用意します。
[csv]
name,gender
Satoshi,male
Mary,female
…
[/csv]
Sequel Proで対象のデータベースに接続します。
Sequel Proの使い方に関しては前回の記事をご覧ください。
「ファイル」から「インポート」を選択します。
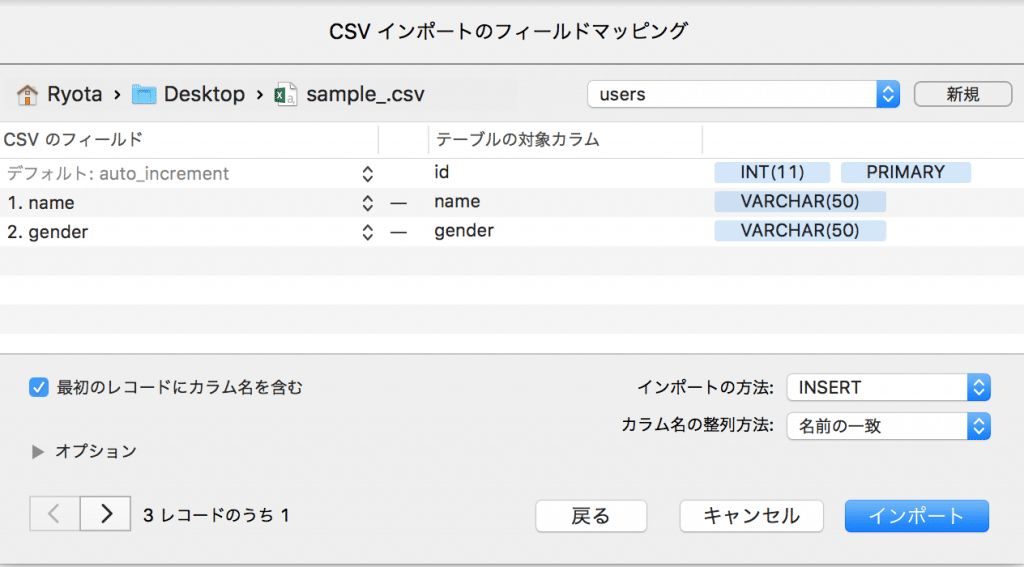
インポートしたいCSVファイルを選択します。
CSVのフィールドとテーブルのカラムが一致しているかチェックします。
よければ「インポート」。
これであとは放置しておけば良いです。
数万ならこれが楽に作業できると思います。
ただ数億になってくると時間がかかるので注意です。
もちろん状況によると思うのですが、2億レコードで400時間くらいかかりそうでした。
もっとも高速なLOAD DATA INFILE
INSERT、IMPORTと紹介しましたが、最後にもっとも高速なLOAD DATA INFILE構文を紹介します。
LOAD DATA LOCAL INFILE file_path INTO TABLE table_name FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 LINES;
こちらで検証された結果ではIMPORTの2倍とかなり高速です。
こちらでも検証がされています。
ざっと調べた範囲ではSequel ProではLOAD DATA INFILE構文がサポートされていないようでした(調査不足の可能性はあります)。
RDSにLOAD DATA INFILE構文を使ってデータをロードする場合は、一度EC2を踏み台にしてMySQLにログインしてLOAD DATA LOCAL INFILEする必要があるようです。
具体的な方法はリンク先の記事にまとめられていたので参照ください。
RDSは書き込み行為でも課金されるので気をつけましょう。
数万程度なら気にしなくていい額ですが、億単位のレコードを試す時は要注意です。
複数ファイルをLOAD DATA INFILE
for f in *.csv; do mysql -u username --password=password -e "LOAD DATA LOCAL INFILE '"$f"' INTO TABLE db_name.table_name FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' IGNORE 1 LINES" done
クエリは-eオプションの直後に置く必要があるのが注意です。
さらに早くするために設定ファイルをカスタマイズ
ここら辺の記事を参考にまとめてみます。
- 漢(オトコ)のコンピュータ道: たった3秒でInnoDBのデータローディングが快適になるライフハック
- 大量件数高速レストア時のmy.cnf(load data infile)@再起を賭けた渡辺の軌跡vol.3
- performance – MySQL load data infile – acceleration? – Stack Overflow
- derwiki – Loading half a billion rows into MySQL
- 【mysql】大容量のCSVファイルをload data infileで読み込めなかった時の対処法 : nymemo
入力後レコード数のチェック
期待した通りデータの入力が完了したかチェックします。
シンプルにCOUNT()を使うならこうですが、これは結構時間がかかります。2億レコードで30sくらい。
SELECT COUNT(*) FROM table_name
InnoDBでは概数になるのですが、以下のようにinformation_schemaを確認することで大体の数がわかります。
MyISAMでは正確な値が取れるようです。
select table_name, table_rows from information_schema.TABLES
参考
- MySQL :: MySQL Connector/Python Developer Guide :: 10.5.4 MySQLCursor.execute() Method
- MySQL :: MySQL Connector/Python Developer Guide :: 10.5.5 MySQLCursor.executemany() Method
- AWSのRDSのmySQLにCSVを一括入力する(EC2経由) | TPB
- 漢(オトコ)のコンピュータ道: たった3秒でInnoDBのデータローディングが快適になるライフハック
- 大量件数高速レストア時のmy.cnf(load data infile)@再起を賭けた渡辺の軌跡vol.3
- MySQLでテーブルの行数を数える | b.l0g.jp
- How to Import Multiple csv files into a MySQL Database – Stack Overflow