Amazon Comprehend Medicalを使ってみた
Amazon Comprehendは構造化されていない自然言語から人物名や地名、そしてそれらの関係性を抽出するサービスです。
Amazon Comprehend Medicalはこれを医療情報に特化させたものです。薬剤名や投薬量などの情報抽出が可能です。ここではAmazon Comprehend Medicalの使い方・性能・料金についてレビューします。
なお、2019年3月18日現在Amazon Comprehend Medicalの制限は以下の通りです。
- 対応言語: 英語
- 入力テキストの最大長: 20,000文字
目次
Amazon Comprehend・Amazon Comprehend Medicalとは
公式から引用します。
Amazon Comprehend は機械学習を使用して、構造化されていないデータのインサイトと関係を明らかにします。このサービスは、テキストの言語を識別し、キーフレーズ、場所、人物、ブランド、またはイベントを抽出し、テキストがどの程度肯定的か否定的かを理解し、トークン分割や品詞を使用してテキストを分析し、テキストファイルのコレクションをトピックごとに自動的に整理します。Amazon Comprehend の AutoML 機能を使用して、組織のニーズに合わせて独自にカスタマイズされたエンティティまたはテキスト分類モデルのカスタムセットを構築することもできます。
https://aws.amazon.com/jp/comprehend/
Amazon Comprehend Medical を使用して、構造化されていないテキストから複雑な医療情報を抽出することができます。このサービスは、医師のメモ、治験の総括報告書 、患者の健康記録などのさまざまな情報源から、病状、投薬、投薬量、強さ、頻度などの医療情報を特定することができます。Amazon Comprehend Medical では、抽出した投薬と試験、治療、および分析をより簡単にするための手順についての情報の間にある関係を見出します。例えば、このサービスは、構造化されていない臨床メモから特定の投薬に関連する特定の投薬量、強さ、および頻度を識別できます。
要するにテキストを突っ込むとどういった単語が含まれているか分析してくれます。Medicalの方は医療特化。カルテなどの分析がメインターゲットかなという印象。
コンソールから利用する
AWSアカウントを解説していることが前提です。持ってない方はこちらを参考にして作成してください。
AWSコンソールからAmazon Comprehendを開き、Try Amazon Coomprehendをクリックします。
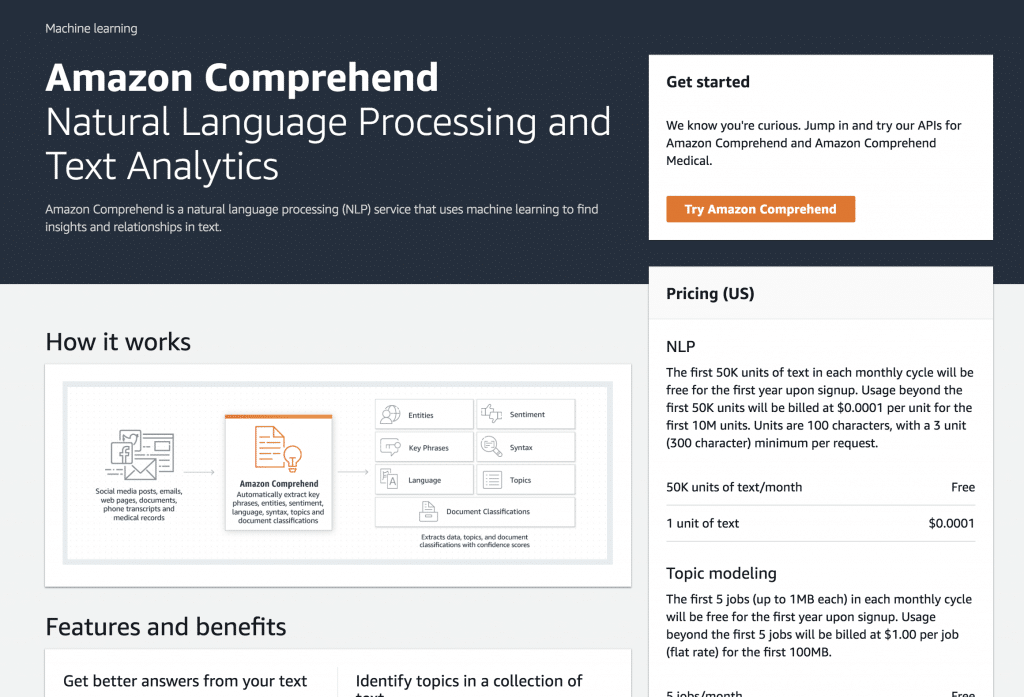
左のリストからComprehend MedicalのReal-time analysisを選択します。
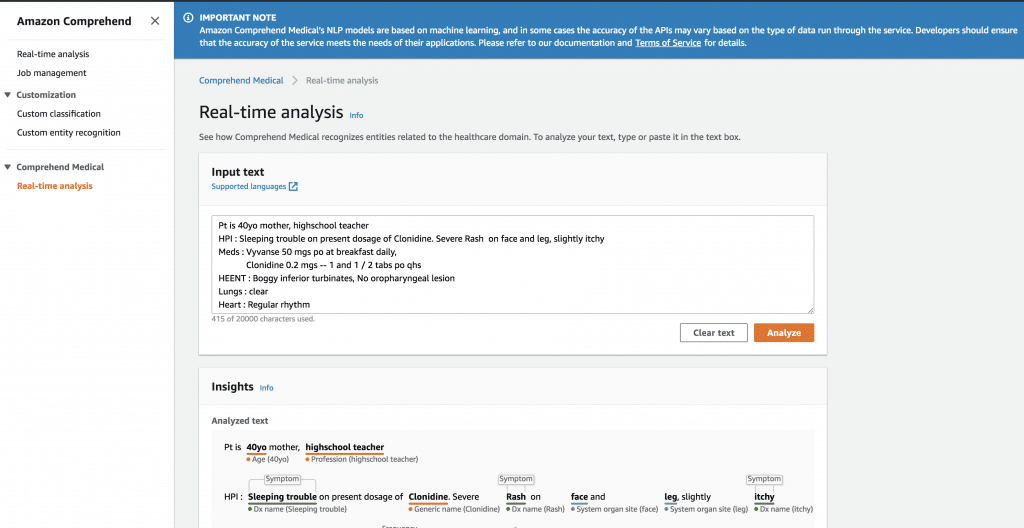
Input textに医療文書を入力してAnalyzeをクリックすれば分析できます。お手軽。
例文は以下の通り、カルテみたいです(患者は40歳の母親、高校教師…)。
Pt is 40yo mother, highschool teacher
https://console.aws.amazon.com/comprehend/v2/home
HPI : Sleeping trouble on present dosage of Clonidine. Severe Rash on face and leg, slightly itchy
Meds : Vyvanse 50 mgs po at breakfast daily,
Clonidine 0.2 mgs — 1 and 1 / 2 tabs po qhs
HEENT : Boggy inferior turbinates, No oropharyngeal lesion
Lungs : clear
Heart : Regular rhythm
Skin : Mild erythematous eruption to hairline
Follow-up as scheduled
分析結果は下のようなものが出力されます。
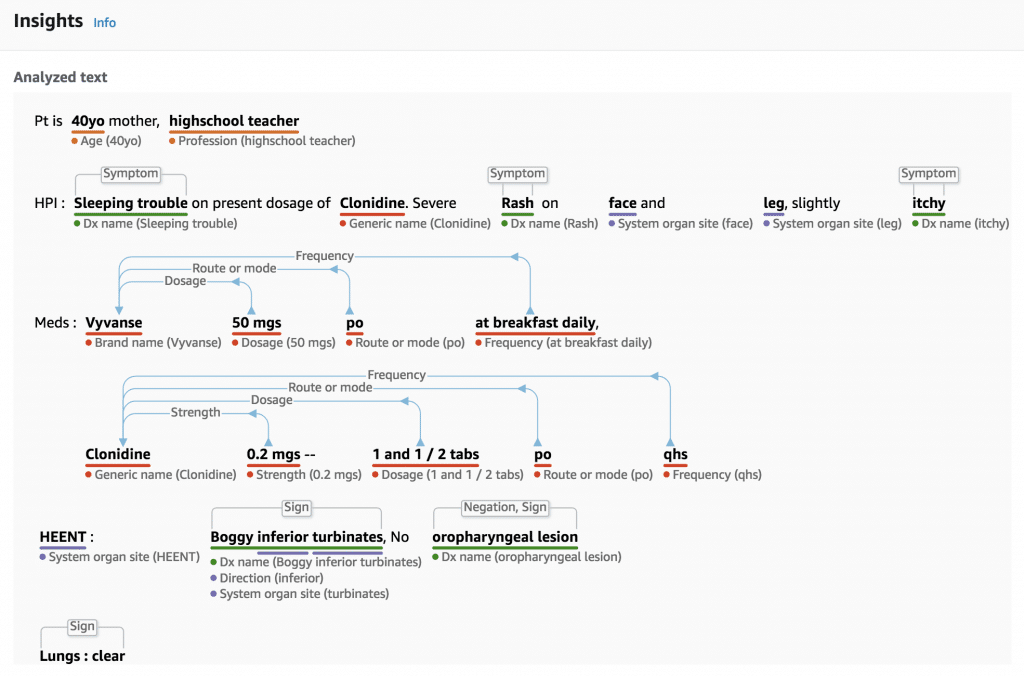
EntityはANATOMY, MEDICAL_CONDITION, MEDICATION, PROTECTED_HEALTH_INFORMATION, TEST_TREATMENT_PROCEDUREの5つのCategoryで分類されます。
さらに各カテゴリ内の詳細な分類であるTypeや追加の情報としてAttribute、Traitが付与されます。
各項目の詳細については以下の説明をご覧ください。
ちょっとした量のテキストを分析してみるには以上のコンソールからの操作で十分です。
APIを利用する
こちらにコードが用意されているのでここではPythonでboto3を使って実装します。
たった3行で取得できます。boto3はawsを扱いやすくしてくれるライブラリです。
import boto3
client = boto3.client(service_name='comprehendmedical', region_name='YOUR REGION')
result = client.detect_entities(Text= 'cerealx 84 mg daily')
entities = result['Entities']
for entity in entities:
print('Entity', entity)
性能評価
今回はBioCreative IV Track2 CHEMDNER CEMのデータセットを用いて、化学物質名・薬剤名の抽出性能を評価します。
CHEMDNERについては以下で解説しました。
Amazon Comprehend Medicalから返ってきた出力をよしなに整形して、CHEMDNERの評価ツールで見ます。
論文3000本分のタイトルとabstractで450 USDでした。
2時間くらいかけてAPIを叩き続けて、出力を評価。
結果はこんな感じ。
shared taskで比較に使われたmicro averaged F-scoreは31%でした。
Evaluation result for 'chemdner_predictions_acm'
Evaluated documents: 2478
Evaluated results: 11238
Hits TP: 5741 FP: 5497 FN: 19610
Macro-averaged results
StdDev precs.: 0.38506 recall: 0.26849 F-scr.: 0.27104
Macro precs.: 0.36260 recall: 0.20828
Macro F-scr.: 0.23408 Avrg P: 0.07452
Macro FAP-s.: 0.11305
Micro-averaged results
Micro precs.: 0.51086 recall: 0.22646
Micro F-scr.: 0.31381 Avrg P: 0.11251
Micro FAP-s.: 0.16563
False PositiveとFalse Negativeを軽く見てみました。
False Positive(誤認識)
まずはFalse Positive(アノテーションされていないのにAmazon Comprehend Medicalが化学物質名・薬剤名と判定したもの)の内確信度が高いものを30個ほど出力してみました(重複除外)。
'panitumumab', 'infliximab', 'rituximab', 'vitamin antioxidants', 'fish oil', 'folic acid modified cationic', 'heparin', 'doxorubicin', 'bevacizumab', 'omega-6 fatty acids', 'cetuximab', 'denosumab', 'omega-3', 'trastuzumab', 'herceptin', 'normal saline', 'hyaluronic acid'
- ミス: vitamin antioxidants, folic acid modified cationic, omega-3: 3/17
- 混合物: fish oil, normal saline: 2/17
- 重合体: heparin, hyaluronic acid: 2/17
- 総称: omega-6 fatty acids 1/17
- モノクローナル抗体: panitumumab, infliximab, rituximab, bevacizumab, cetuximab, denosumab, trastuzumab, herceptin: 8/17
- 抗がん剤(モノクローナル抗体以外の): doxorubicin: 1/17
はっきりとミスと言えるのは3/17でした。これらは不自然に単語を抜き出してきているので確かにFalse Positiveと言えるでしょう。
また化学物質とは言えない混合物として魚油、生理食塩水などが2/17含まれました。
判断に悩むものとしてはヘパリンやヒアルロン酸などの重合体が2/17。
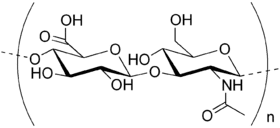
オメガ脂肪酸のように複数の物質の総称が1/17。
CHEMDNERではこれらを含まないルールでしたがAmazonが薬剤名として判断するのも止むなしという感想です。
半数近くあるモノクローナル抗体(ほとんどは抗がん剤)やそれ以外の抗がん剤も薬剤名として判断されるだろうなという感じです。
CHEMDNERで抗体や高分子は含まないという判断基準があったのでしょうか。再度確認が必要です。
False Negative(取りこぼし)
逆にFalse Negative(CHEMDNERでは化学物質としてアノテーションされたのにAmazonが見逃したもの)も30個ほど適当にピックアップして重複を除外してみました。
'nitric oxide', 'saquinavir', 'docosahexaenoic acids', 'darunavir', 'bicarb', 'mg', 'ritonavir', 'adp', 'aluminum phosphide', 'no', '(25)mgpmc16', 'atp', 'sildenafil', 'monocarboxylate', 'docosahexaenoic acid', 'methylmercury', 'alp'
基本的にシンプルに把握漏れという感じです。一酸化窒素とかATPとか確かに臨床コーパスを利用したとしたら投与する薬剤として以外の文脈でも出たから検出しづらかったのかなという気持ち。それぐらいの憶測しかできません。
総評
総じて分析すると、False Positiveに関してはAmazon Comprehend MedicalはCHEMDNERと比較してより臨床的な関心が高いことが原因と思われました。
一方、False Negativeに関しては把握漏れと言える内容だったので学習に用いたコーパスが偏っていたのかな、という感じです。
シンプルにAmazon側が想定している医療文書(それも臨床よりのもの)に使うなら良いんじゃないでしょうか。今回は触れませんでしたが、病名や患者に関する情報も抽出できるのはかなり有用だと思います。
一方で、ピンポイントに「薬剤名を抜き出したい」などの用途に使う場合は上述したような取りこぼしや誤認識に注意が必要そうです。
アンサンブル的に使うなら良いでしょうが、もっと良いツールやモデルがあるので第一選択肢にはならないでしょう。
料金
Amazon Comprehend Medicalの利用料金は以下の通りです。
100文字が1ユニットで、ユニットあたりに料金がかかります。

今回の分析では5万円弱かかりました。がびょーん。誰かご飯おごってください。まぁクレジット使ったんですが。
他にも条件を満たせば無料利用枠が与えられるっぽいので詳しくは公式をご覧ください。