NLP state of the artをお手軽に使えるflair
A very simple framework for state-of-the-art NLP.
zalandoresearch/flair Github
NLPのsotaを超簡単に実装できるフレームワークflairを使ってみました。
READMEのふわふわ和訳と触ってみた感想が主な内容です。
ふわふわ和訳はふわっと雰囲気を伝えるだけです。詳しいことは原文を参照してください。
結構頻繁に更新があるので、エラーが出たら公式をチェックしてください
目次
flairとは
- 強力なNLPライブラリ: お手元のテキストを使ってnamed entity recognition, part-of-speech tagging, sense disambiguation, classification(固有表現抽出, 品詞タグ付け, 曖昧性解消, 分類)のsotaを試せるよ
- 多言語対応: 日本語はちょっとだけ
- 単語埋め込みライブラリ: BERTとかELMoも簡単に使えるよ
- PyTorch NLPフレームワーク: PyTorchベースだよ
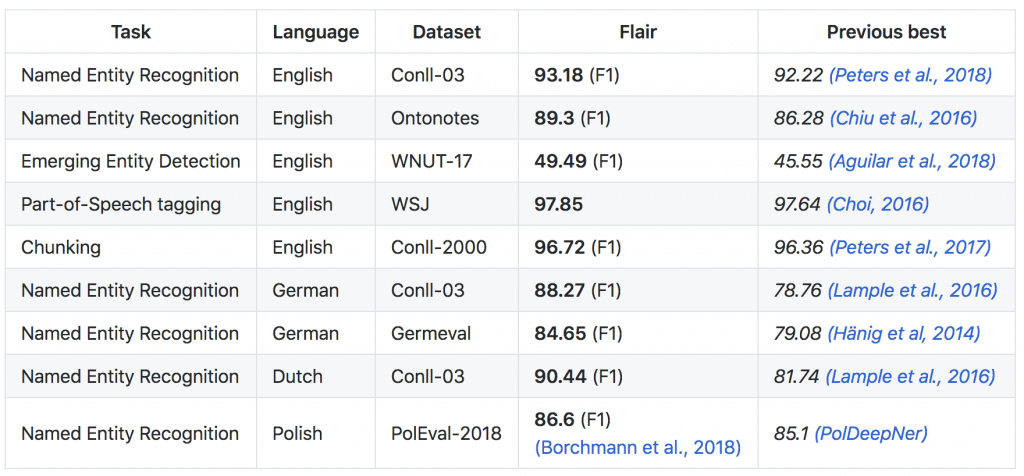
Sotaと比較
flair使うと既存のSotaを超えたよ。
クイックスタート
依存関係
- PyTorch 0.4+
- Python 3.6+
まずはpipでインストール。
pip install flair
あとはExample, Tutorialsを触れば理解できるはず。
Tutorialsはとりあえず1, 2, 3やれば一通りわかるかなって感じです。
まぁとにかく簡単です。GPU仕様の指定とかもしなくていいです。あれば使うしなければCPUを使う賢い子
Example
flairが用意するNERタガー使ってみるとこんな感じでタグ付けできます。
タガーのインポートは初回時に少し時間がかかります。
from flair.data import Sentence
from flair.models import SequenceTagger
sentence = Sentence('I love Berlin .')
tagger = SequenceTagger.load('ner')
tagger.predict(sentence)
for entity in sentence.get_spans('ner'):
print(entity)
LOC-span [3]: "Berlin"
直接SequenceTaggerクラスのload()メソッドを見ればどんな種類のタグ付けができるかわかります。
NER、PoS、chunkとそれの派生系がだいたい20種類強。
Tutorial 1: Basics: SentenceとToken
flairではTokenオブジェクトやTokenのリストであるSentenceオブジェクトをメインに扱います。
文章単位でSentenceオブジェクトに突っ込めばおっけー。
from flair.data import Sentence
sentence = Sentence('The grass is green .')
print(sentence)
Sentence: "The grass is green ." - 5 Tokens
一個ずつTokenを取り出して表示してみます。
Tokenはtoken idとTokenの値(”green”)で構成されます。
for token in sentence:
print(token)
Token: 1 The
Token: 2 grass
Token: 3 is
Token: 4 green
Token: 5 .
このtoken idやindexを用いてSentenceからTokenを取り出すこともできます。token idは1から始まる点に注意!
範囲取得することも可能です。
print(sentence.get_token(4))
print(sentence[3])
print(sentence[:3])
Token: 4 green
Token: 4 green
[Token: 1 The, Token: 2 grass, Token: 3 is]
未処理のテキストをそのまま突っ込み、同時にトークナイズすることも可能です。
“… green.”と文末の単語とピリオドが分割されていませんが、use_tokenizerオプションを有効にすることでよしなに処理してくれます(tokenizerにはsegtokが使われるようです)。
sentence = Sentence('The grass is green.', use_tokenizer=True)
print(sentence)
Sentence: "The grass is green ." - 5 Tokens
またTokenオブジェクトにはタグを付与することができます。add_tag()メソッドにタグのタイプ (ner)と値(color)を渡しましょう。タグのタイプには任意の文字列が使えます。confidenceオプションで確信度を追加できます(デフォルトは1.0)。
Sentenceオブジェクトのto_tagged_string()メソッドでタグ付きで出力できます(ちょっと見辛いですね)。
sentence[3].add_tag('ner', 'color')
print(sentence.to_tagged_string())
The grass is green <color> .
逆にTokenオブジェクトからタグを取得したいときはタグのタイプを指定してget_tag()メソッドを使えば良いようです。
タグはLabelオブジェクトで、タグの値と確信度で構成されます。
print(sentence[3].get_tag('ner'))
print(sentence[3].get_tag('ner').value)
print(sentence[3].get_tag('ner').score)
color (1.0)
color
1.0
Sentenceにラベルをつける事も可能です。
Tokenにタグを付与した時と同様add_label()メソッドで文章に丸々labelを付与できます。またadd_labels()メソッドを使えば一度に複数のラベルを付与できます。
sentence = Sentence('France is the current world cup winner.')
sentence.add_label('sports')
sentence.add_labels(['sports', 'world cup'])
Sentenceインスタンスを作成するときにラベルを渡すこともできます。
sentence = Sentence('France is the current world cup winner.', labels=['sports', 'world cup'])
Tutorial 2: Tagging your Text: テキストのタグ付けとテキスト分類
タグ付け
学習済みのモデルでテキストをタグ付けします。
Exampleでやったようにまずはタガーをロード。
from flair.models import SequenceTagger
tagger = SequenceTagger.load('ner')
predictメソッドにSentenceオブジェクトを突っ込むだけ!
表示するときはto_tagged_string()メソッドを使う。
sentence = Sentence('George Washington went to Washington .')
tagger.predict(sentence)
print(sentence.to_tagged_string())
George <B-PER> Washington <E-PER> went to Washington <S-LOC> .
sentence.get_spans()メソッドを使えば、タグが付いている固有表現のSpanオブジェクトのリストが帰ってきます。
Spanオブジェクトにはタグの値、固有表現の位置(token id)、テキストで構成されます。
sentence.get_spans('ner')
[<PER-span (1,2): "George Washington">, <LOC-span (5): "Washington">]
to_dict()メソッドを使えばオフセットや確信度など追加情報を得られます。
print(sentence.to_dict(tag_type='ner'))
{'text': 'George Washington went to Washington .',
'labels': [],
'entities': [{'text': 'George Washington',
'start_pos': 0,
'end_pos': 17,
'type': 'PER',
'confidence': 0.9967881441116333},
{'text': 'Washington',
'start_pos': 26,
'end_pos': 36,
'type': 'LOC',
'confidence': 0.9993709921836853}]}
文分割されていない文書を扱うときは、
①segtokの文分割
②Sentenceクラスのトークナイズ
のを利用すればおっけー。
text = "This is a sentence. This is another sentence. I love Berlin."
from segtok.segmenter import split_single
sentences = [Sentence(sent, use_tokenizer=True) for sent in split_single(text)]
tagger: SequenceTagger = SequenceTagger.load('ner')
tagger.predict(sentences)
segtok使ったことなかった。要は文ごとに区切ったstrのリストにしてあげればいいだけなので馴染みの深いnltkでもできますし、自前の文分割機能を使ってもおっけー。
(ピリオドで区切るだけじゃん!と思うかもしれないですが文分割は意外と難しいので先人の知恵を使うことをオススメします)
用意されてる学習済みモデルと性能はこんな感じ。最新情報はリンク先を見てね。
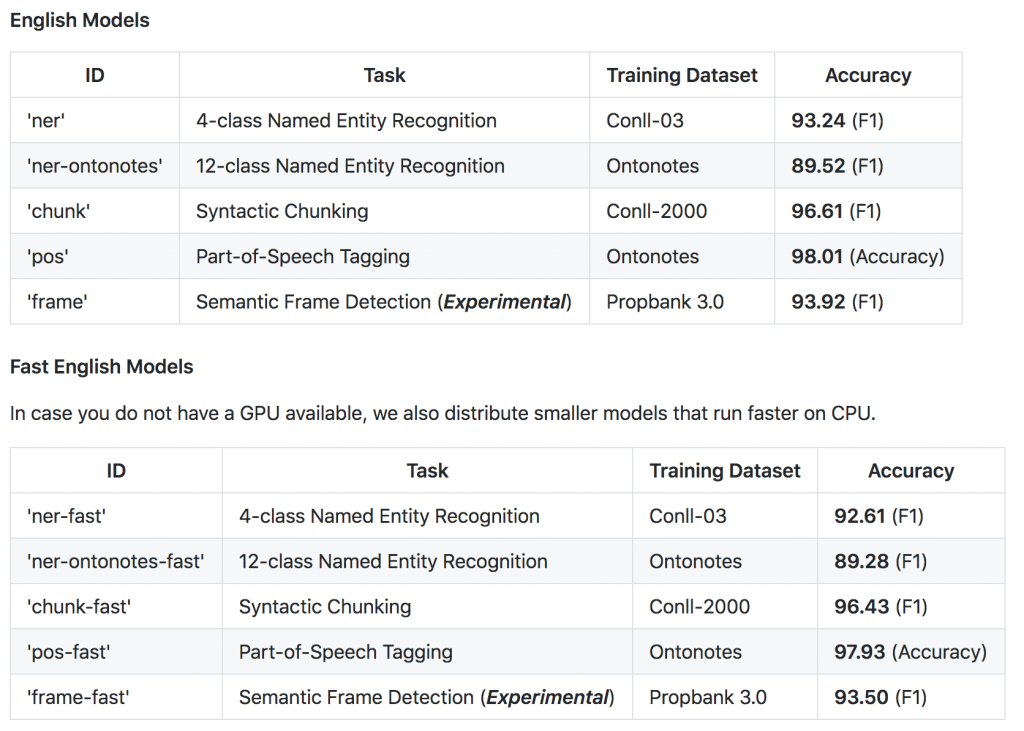
他にもドイツ語、フランス語、オランダ語に対応していたり、複数言語が混在する文章も扱えるみたいだけど、あまり関心がないので詳しくは見てないです。
テキスト分類
タグ付けだけでなく、テキスト分類も紹介します。初回は分類器のダウンロードに数分かかる。
感情分析を使ってみます。
from flair.models import TextClassifier
classifier = TextClassifier.load('en-sentiment')
sentence = Sentence('This film hurts. It is so bad that I am confused.')
classifier.predict(sentence)
print(sentence.labels)
[NEGATIVE (1.0)]
英語のsentiment(感情分析)と、ドイツ語のoffensive language(暴言検知?)が用意されています。

Tutorials 3: Word Embeddings: 単語埋め込み
ここではWordEmbeddingsクラスの使い方に触れます。
GloVeを使ってみましょう。インスタンス生成時に引数で使いたいembeddingsを指定します。
from flair.embeddings import WordEmbeddings
glove_embedding = WordEmbeddings('glove')
あとはembed()メソッドにSentenceインスタンスを突っ込むだけ。
すると以下の通りsentence内のTokenそれぞれにembeddingが付与されます。
sentence = Sentence('The grass is green .')
glove_embedding.embed(sentence)
for token in sentence:
print(token)
print(token.embedding)
Token: 1 The
tensor([-0.0382, -0.2449, 0.7281, -0.3996, 0.0832, 0.0440, -0.3914, 0.3344,
-0.5755, 0.0875, 0.2879, -0.0673, 0.3091, -0.2638, -0.1323, -0.2076,
0.3340, -0.3385, -0.3174, -0.4834, 0.1464, -0.3730, 0.3458, 0.0520,
0.4495, -0.4697, 0.0263, -0.5415, -0.1552, -0.1411, -0.0397, 0.2828,
0.1439, 0.2346, -0.3102, 0.0862, 0.2040, 0.5262, 0.1716, -0.0824,
-0.7179, -0.4153, 0.2033, -0.1276, 0.4137, 0.5519, 0.5791, -0.3348,
-0.3656, -0.5486, -0.0629, 0.2658, 0.3020, 0.9977, -0.8048, -3.0243,
0.0125, -0.3694, 2.2167, 0.7220, -0.2498, 0.9214, 0.0345, 0.4674,
1.1079, -0.1936, -0.0746, 0.2335, -0.0521, -0.2204, 0.0572, -0.1581,
-0.3080, -0.4162, 0.3797, 0.1501, -0.5321, -0.2055, -1.2526, 0.0716,
0.7056, 0.4974, -0.4206, 0.2615, -1.5380, -0.3022, -0.0734, -0.2831,
0.3710, -0.2522, 0.0162, -0.0171, -0.3898, 0.8742, -0.7257, -0.5106,
-0.5203, -0.1459, 0.8278, 0.2706])
Token: 2 grass
tensor...
(GloVeのembeddingは100次元のPyTorchベクトル)
英語はいくつかの種類のembeddingsが用意されています。
FastTextのみ、他30言語くらい用意されてました(日本語もあるよ)。
将来的には”ja-twitter”みたいな感じで各言語様々な種類のembeddingを用意したいんだろうけど、未対応
Character Embeddings
文字レベルのembeddingを使いたい場合はCharacterEmbeddingsクラスが役に立ちます。
文字レベルのembeddingを使うには通常トークンを1文字ずつRNNに突っ込んでベクトルに変換、1文字ごとのベクトルを連結、といった階層的な処理が必要です。
flairではそういったまどろっこしいこと(1文字ずつ扱うなど)はしなくてもよく、文章をそのままCharacterEmbeddingsのembed()メソッドに突っ込めばおっけー。
from flair.embeddings import CharacterEmbeddings
embedding = CharacterEmbeddings()
sentence = Sentence('The grass is green .')
embedding.embed(sentence)
試しに先頭単語のembeddingを見てみると、こんな感じ。
sentence[0].embedding
tensor([-0.0570, 0.1016, -0.0710, -0.0720, -0.0867, 0.0830, -0.0529, -0.1637,
0.0233, -0.0829, 0.1577, 0.0338, -0.1077, -0.0499, -0.0949, 0.1175,
-0.0105, -0.0076, 0.1949, 0.2380, -0.0449, 0.0150, 0.1351, -0.2148,
0.0993, 0.1501, -0.2259, 0.0787, -0.0225, -0.2227, 0.0861, -0.2147,
0.0473, 0.0842, -0.1521, -0.0497, 0.0471, 0.0100, 0.0802, -0.1897,
-0.2601, 0.0160, 0.0584, 0.0072, 0.0634, 0.1042, -0.1923, -0.0821,
0.0133, 0.0382], grad_fn=<CatBackward>)
以降はWordEmbeddingsと同様に扱える、はず。
Byte Pair Embeddings
サブワードレベルのembedding。word embeddingsより軽くて同等の性能らしい。
詳しくはGithub、論文のリンクを貼っておきます。
Stacked Embeddings
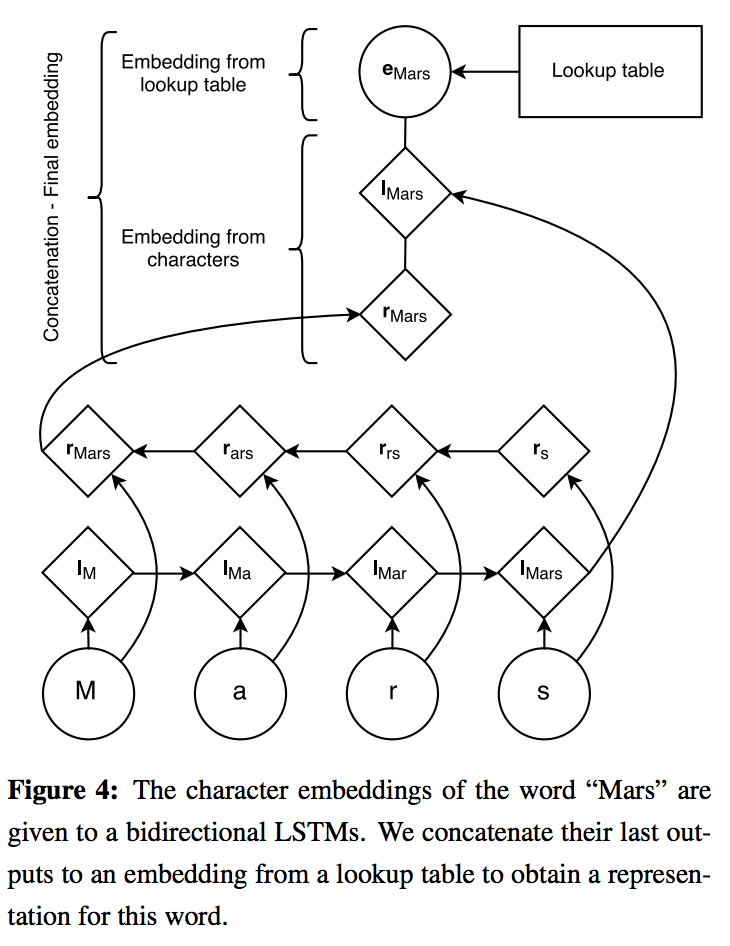
すごく大事なとこ。
例えば以下のLampleのモデルのように文字レベルのembeddingと単語レベルのembeddingを連結させて使いたいときにはStacked Embeddingsクラスを使います。
使い方はシンプルで、まず複数のembeddingsを用意します。
from flair.embeddings import WordEmbeddings, CharacterEmbeddings
glove_embedding = WordEmbeddings('glove')
character_embeddings = CharacterEmbeddings()
それらのインスタンスをStackedEmbeddingsのembeddingsオプションに突っ込むだけ!
GloVeの100次元と、character embeddingsの50次元をconcatした150次元のembeddingが出来上がります。
from flair.embeddings import StackedEmbeddings
stacked_embeddings = StackedEmbeddings(
embeddings=[glove_embedding, character_embeddings])
あとはこれまで通りの使い方。
sentence = Sentence('The grass is green .')
stacked_embeddings.embed(sentence)
for token in sentence:
print(token)
print(token.embedding)
Tutorials 6: Creating a Corpus: コーパス
昨今のコーパスは以下のような形態になっていることが多いです。
以下の例では単語が行方向に続き、列方向に単語・PoSタグ・NERタグとなっています。
George N B-PER
Washington N I-PER
went V O
to P O
Washington N B-LOC
上記のようなテキストデータを読み込むときは、以下のように”columns”で列番号と列名をdict型で渡してあげます。
*TaggedCrpusは 0.4.2で削除されました!前のチュートリアルを読んでいる人は注意!逆に0.4.1以前ではColumnCorpusがないのでアップデートしましょう。
from flair.data import Corpus
from flair.datasets import ColumnCorpus
# define columns
columns = {0: 'text', 1: 'pos', 2: 'ner'}
# this is the folder in which train, test and dev files reside
data_folder = '/path/to/data/folder'
# init a corpus using column format, data folder and the names of the train, dev and test files
corpus: Corpus = ColumnCorpus(data_folder, columns,
train_file='train.txt',
test_file='test.txt',
dev_file='dev.txt')
ちなみにいくつかのデータセットが用意されていて、load_column_corpus()で呼び出すことができます。この際に自動で’~/.flair/datasets/’ディレクトリにデータセットをダウンロードしてくれます。
corpus = NLPTaskDataFetcher.load_corpus(NLPTask.CONLL_2000)
ただしCoNLL 2003 (en)に関しては、NLPTaskクラスで定義されているにも関わらず自動でダウンロードすることはできません(ロイターのデータが再配布禁止?)。
なので使いたい場合は’~/.flair/datasets/’ディレクトリにデータを置いてあげる必要がありました。ちなみに、train, dev, testを自動で分けてくれるのですが、そこらへんの処理はここら辺に書いてあります。
なのでコードを読み解けば、’~/.flair/datasets/conll_03’ディレクトリを作って、ファイルをコピペしてあげればおっけー。
print(corpus)
2019-04-10 03:43:24,233 Reading data from /home/ubuntu/.flair/datasets/conll_03
2019-04-10 03:43:24,234 Train: /home/ubuntu/.flair/datasets/conll_03/eng.train
2019-04-10 03:43:24,235 Dev: /home/ubuntu/.flair/datasets/conll_03/eng.testa
2019-04-10 03:43:24,286 Test: /home/ubuntu/.flair/datasets/conll_03/eng.testb
TaggedCorpus: 14987 train + 3466 dev + 3684 test sentences
またTaggedCorpusクラスにはdownsample()メソッドがあり、これによりfloatで指定した割合の少量サンプルを呼び出すことができます。
downcorpus = corpus.downsample(0.1)
print(downcorpus)
TaggedCorpus: 1499 train + 347 dev + 369 test sentences
1割だけ呼び出すことができました。
Tutorial 7: Training a Model: 学習
まずはコーパスの呼び出し。Tutorial 6のコーパスのおさらいですね。
とりあえずチェックするだけでよければdownsample()メソッドをcorpusに適用しデータを減らしましょう。
from flair.data import TaggedCorpus
from flair.data_fetcher import NLPTaskDataFetcher, NLPTask
from flair.embeddings import TokenEmbeddings, WordEmbeddings, CharacterEmbeddings, StackedEmbeddings
from typing import List
corpus: TaggedCorpus = NLPTaskDataFetcher.load_corpus(NLPTask.CONLL_03)
print(corpus)
2019-04-10 03:43:24,233 Reading data from /home/ubuntu/.flair/datasets/conll_03
2019-04-10 03:43:24,234 Train: /home/ubuntu/.flair/datasets/conll_03/eng.train
2019-04-10 03:43:24,235 Dev: /home/ubuntu/.flair/datasets/conll_03/eng.testa
2019-04-10 03:43:24,286 Test: /home/ubuntu/.flair/datasets/conll_03/eng.testb
TaggedCorpus: 14987 train + 3466 dev + 3684 test sentences
タグの辞書を作ります。NERタグのPER, ORG, LOC, MISCと、IOBESフォーマットの組み合わせ、そして<START>, <STOP>, <unk>の計20種類のタグを用いた系列ラベリングです。
tag_type = 'ner'
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
print(tag_dictionary.idx2item)
[b'<unk>', b'O', b'S-PER', b'S-ORG', b'S-LOC', b'S-MISC', b'B-ORG', b'E-ORG', b'I-ORG', b'B-LOC', b'E-LOC', b'B-PER', b'E-PER', b'B-MISC', b'E-MISC', b'I-PER', b'I-MISC', b'I-LOC', b'<START>', b'<STOP>']
20種類 = len([‘PER’, ‘ORG’, ‘LOC’, ‘MISC’]) * len([‘I’, ‘B’, ‘E’, ‘S’]) + len([‘O’, ‘<START>’, ‘<STOP>’, ‘<unk>’])
embeddingはTutorial 3のおさらいです。StackedEmbeddingsに複数のembeddingsを渡せば、以下のようにGloVEのword embeddingsと文字レベルのembeddingsを合わせて利用できます。
embedding_types: List[TokenEmbeddings] = [
WordEmbeddings('glove'),
CharacterEmbeddings(),
]
embeddings: StackedEmbeddings = StackedEmbeddings(embeddings=embedding_types)
SequenceTaggerクラスに隠れ層のサイズやembeddings、タグの種類などを渡してインスタンス化。
from flair.models import SequenceTagger
tagger: SequenceTagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=True)
ここから新要素。ModelTrainerクラスにtaggerとcorpusを渡します。
from flair.trainers import ModelTrainer
trainer: ModelTrainer = ModelTrainer(tagger, corpus)
あとは学習を開始するだけ。train()メソッドの第一引数は学習過程のログなどが吐き出されるディレクトリの指定です。max_eopchはちょろっと確認するだけなので10にしておきます。
ここに経過が残るため、学習を中断しても途中から再開できます。よくできてる。
trainer.train('logs/',
learning_rate=0.1,
mini_batch_size=32,
max_epochs=10)
2019-04-10 03:43:57,190 ----------------------------------------------------------------------------------------------------
2019-04-10 03:43:57,191 Evaluation method: MICRO_F1_SCORE
2019-04-10 03:43:57,193 ----------------------------------------------------------------------------------------------------
2019-04-10 03:43:57,866 epoch 1 - iter 0/469 - loss 74.72248077
2019-04-10 03:44:25,785 epoch 1 - iter 46/469 - loss 15.65760789
...
最後にご丁寧に学習曲線のプロットまで用意されています。
%matplotlib inline
from flair.visual.training_curves import Plotter
plotter = Plotter()
plotter.plot_training_curves('logs/loss.tsv')
“logs/”ディレクトリにpngファイルで保存されます。

テストはこんな感じ。
model = SequenceTagger.load_from_file('logs/final-model.pt')
sentence = Sentence('I love Berlin')
model.predict(sentence)
print(sentence.to_tagged_string())
所感
Tutorialがとてもわかりやすかったし、直感的に使えて嬉しい。
以降もTutorialは続き、BERTやELMoを使ったり、自前のモデルを学習したりと充実してます。
- Tutorial 4: Using BERT, ELMo, and Flair Embeddings
- Tutorial 5: Using Document Embeddings
- Tutorial 7: Training your own Models
- Tutorial 8: Optimizing your own Models
- Tutorial 9: Training your own Flair Embeddings
自分で何かしらのタスクを回して性能を見たかったんですが、力尽きたので今回はここまで。