がんのin vivo論文アノテーション①固有な語彙
がんのin vivo論文をアノテーションします。
今回は対象となる論文*とそれ以外を選り分けました。
*対象論文:動物実験(特にがん細胞の移植、骨髄移植)を含む論文
本記事では便宜的に上記の対象論文、対象条件を指してin vivoと表現します。また対象外を対比してin vitroと表現します。
厳密にはin silicoやヒトの統計分析も含んでいますがご了承ください。
目次
背景
動物実験をする前には先行研究を調べます。自分が行いたい実験と似た事例を調べて条件を大まかに決めるのです。
例えば「Aというマウスを使ってこんながんのモデルを作り、Bという薬剤が致死率を改善するか確認したい」とします。
ちょっと条件が異なる先行研究、例えば、
- Bに似た別の薬剤B’を使っている
- 薬剤の投与経路が違う
- 使っているがん細胞が違う
をいくつか調べて、幅をもたせた実験条件を試します。
ここでは、いくつかの先行研究の結果から「薬剤Bは大体10~100mgで効果を見ることができる」と判断したとします。
次に、実際に少量のマウスに10, 30, 100mg(僕は大体3倍置きに区切ってました)の薬剤を投与して一番効果的な実験条件を決定します。
ここまでを「予備実験」と言います。実験条件を決めるための実験です。
ここまで前準備をしてようやく、論文に掲載するデータを取るための実験(「本実験」)を行えます。
さて予備実験に関してですが、労力、時間、資金あらゆるコストを考えても少ない方がいいに決まっています。
上の例でいうと、10, 30, 100mgの実験の中で30mgが一番良かった場合、何も問題はありません。30mgで本実験に移行できます。
しかし、10mgの結果がよかった場合は困ります。もっと少ない方が適切かもしれないからです。
すると今度は3, 10, 30mgで予備実験をしなくてはなりません。全然足りないなと勘が働いたら、0.3, 1mgも追加するかもしれません。
要するに、予備実験というのは下に凸な関数の最小値を求める問題とも言えます。
初期条件と探索方法をミスればべらぼうな探索回数が必要になってしまいます。
さて予備実験を効率的に行うには以下の2つの選択肢があります。
- 先行研究を十分に調べて確度の高い実験条件を設定、少量の動物実験で確認する
- 多くのマウスを使って幅の広い複数条件で一気に確認する
2つの戦略でトレードオフになっているのは「実験動物の量」と「調査時間」です。
先行研究から実験条件を抜き出すというのはなかなか面倒です。
後者の「過去の実験など知ったことか、大量にマウス使えばわかるだろ」というゴリ押し戦略は、マウスのコストを考えなければ「効率的」な手法です。
僕は免疫系の研究室でアレルギーの研究をしていました。
多くの論文を読めば実験条件を絞ることができると考えていたのですが、大抵論文を読んでいると先輩や指導教官に「サボるな手を動かせ」と言われたものです。
その度に、先行研究を判断材料に加えないのは勿体無いなと思っていました。
そんな背景があったのですが、そもそも「実験動物の量」と「調査時間」がトレードオフになっているのを解消するべきだなと思い至りました。
なんでこんなに先行研究調べづらいのか、と。
そもそも先行研究の実験条件が論文内に非構造的なテキストとして散らかっているのが問題なわけです。
自分が行いたい実験条件を入力したら、近しい過去の実験条件を一覧で表示できたら予備実験の設定がはるかに効率的に行えます。
というわけで、最近はがんの論文から動物実験の条件を抽出することに躍起になっていました。
モチベーションは、「ムダな動物実験に使われる動物を減らしたい」です。
「ムダな」っていうのは十分に先行研究を調査したらやる必要のなかった実験という意味です。
例えば、先行研究を参考にすれば大体10~100mgが妥当とあたりがつけられるのに、ろくにあたりも付けず1~10ngから始めた結果「もっと多くてもいいな」、「もっと多くてもいいな」と延々と増やしていくのはムダに該当します。
予備実験や動物実験自体は現状、必要なプロセスだと考えています。
緩やかに、合理的に代替されていくべきだと思いますが、「来年から動物実験0にしよう」などという過激な主張には断固反対しています。
そういう意味で、僕は決して動物実験廃止派ではないので悪しからず。
先行研究
科学論文からの情報抽出という点でいろいろ調べてみました。
科学論文のabstructからknowledge baseを作成し、論文を検索・比較しやすくする試みや、
生命科学の実験プロトコルを構造的に記述する試みが見つかりました。
ただ実際に研究に携わった身としては、これらの手法が提供する情報は(予備実験で先行研究を調査するという目的では)物足りないと感じました。
そこでEXACT2をベースとしてより狭い領域に適用した構造的な情報の抽出が必要だと判断しました。
がんの論文を集める
抽出する情報を細かくするのであれば、領域は絞った方がやりやすいと思います。
そこでまずは 「がん」に絞って情報抽出と構造化にトライします(がんという領域もかなり広いのですが)。
オープンアクセスのNature Communication、Scientific Reportsから「がん」に関連する論文を集めます。
単に「cancer」という文言で検索するのではなく、Subjectをcancerと指定することでnatureがタグ付けした関連論文を見つけることができます。
この検索条件で8500件ほどヒットしました。
論文は主にAbstruct, Introduction, Results, Discussion, Methodsを読めば大体全容が理解できるようになっています。
今回は動物実験の条件を抽出したいので主にMethodsが関心の対象です(論文によってはMaterials and methodsなど表現が変わることもあるので注意)。
Methodsでは論文内に掲載した実験の条件を記載します。いくつかのサブセクション(下図の赤枠)に分かれています。
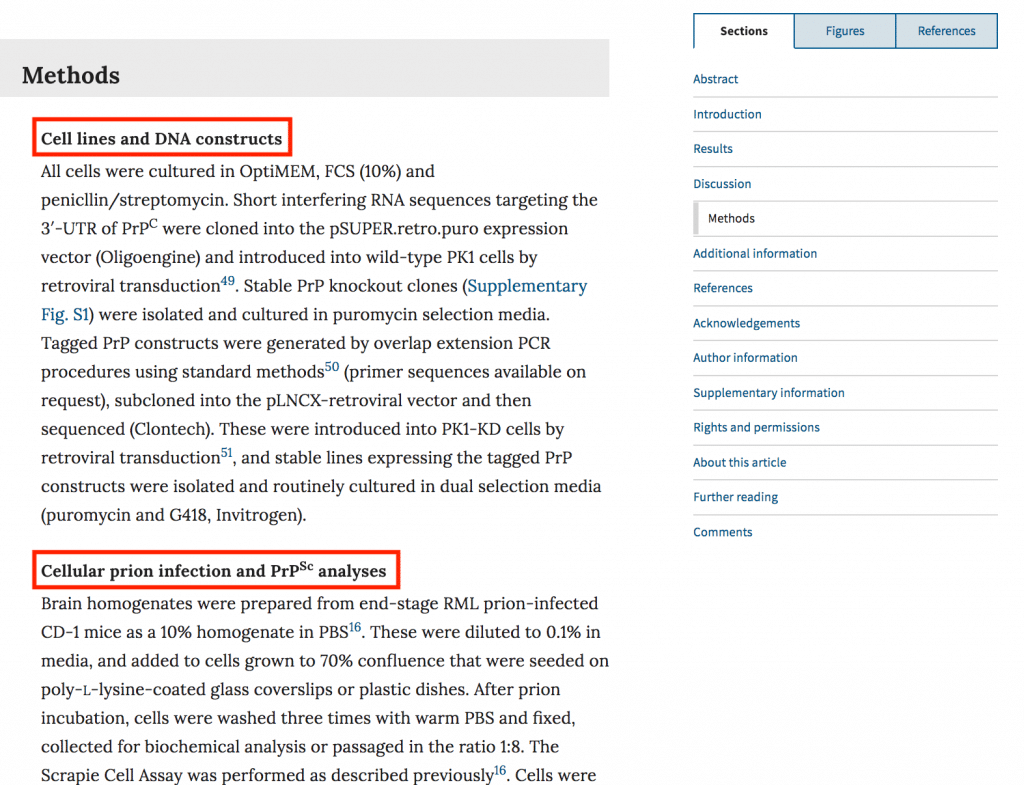
一旦csvファイルにまとめて、以下のようにサブセクションで区切って表示します。
論文95本のMethodsが850のサブセクションに分割されました。
(もともと100本を解析対象にしたのですが、うち5本はMethodsが含まれなかったり構造が一律に扱えなかったりで省きました)

in vivoの論文を集める
さてcancerに該当する論文から今回はさらにin vivo(動物実験)のものだけを扱います。
⇔in vitro(試験管内実験)
先ほどの850のサブセクションを一つ一つ眺めて、後述する条件に合致するものにラベルをつけていきました(別のcsvファイルを開いて0/1を入力し続ける)。
ここでゴールを再確認します。
「がんの基礎実験における動物実験の記述を構造的に落とし込むこと」
特にモデル構築に着目したので、マウスを落とした後に行う分析やin vitroの実験(PCRなど)に関しては省くことにしました。
よって以下の内容に関するサブセクションをプロトコルの構築に必要な文章としてチェックします。
必要な文章
- マウス(近郊系)
- トランスフェクション(遺伝型)
- 細胞培養、移植(がん細胞)
- 投薬(薬剤)
逆に以下の記述は解析の対象外としました。
- 染色、撮影
- タンパクや遺伝子の計測
- マウスの扱い方(動物愛護的な観点)
- 統計処理
さて、一つの論文の中に上記の必要な文章が1つでもあればin vivo(の内容が含まれる)論文、1つもなければそれ以外の論文*であるとラベル付けしました。
(それ以外の論文とは、試験管内実験であるin vitro論文やシミュレーションであるin silico論文、また今回の解析対象外である人のデータの分析などです)
以上のラベル付けによって、50.5%(論文95本中48本)がin vivoの内容を含む解析対象の論文でした。
アノテーションはこちらの論文だけを使うのですが、その前に今後in vivo / in vitroの分類器を作ることを考えて軽く分析してみます。
95本の論文にからかなりざっくり語彙を取得しました。
前処理は文末のピリオド、文間のカンマ、単語の頭・尾のかっこ、URL、数字(数字だけで構成される場合)を除去しました。
語彙は15415でした。
さて、各論文のMethodsにこれらの語彙が含まれるかを調べ、以下の計算を行いました。
(対象論文に含まれる回数 – 対象外論文に含まれる回数)/(論文数)
数値が大きいほどin vivo論文に固有な単語で、小さいほど対象外論文に固有な単語であることになります(範囲は-1~1ではないし、トントンだったら0とは限らないのでざっくり確認用の参考値です)。

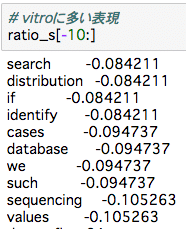
mouse, mice, animalなどの動物を指す単語、injected, injectionなど注射に関連する単語がin vivo特有で観察されたようです。納得です。
逆にin vitro固有のものってのはあまりなかったです(絶対値が小さいので)。
これはin vivo論文にもin vitroの実験が含まれるからというように理由付けられます。
乱暴に言えば、(語彙の観点から)in vivo論文はin vitro論文に動物実験を加えたものだと理解できました。
おまけ
語彙に関してはあらかた感覚で掴んでいた予想通りの結果でしたが、検証ができたので自信を持てます。
次回以降、今回選り分けたin vivo論文48本をいよいよBratでアノテーションします。
今回のような論文から動物実験に関する情報抽出や構造化に関心がある方はぜひ私のTwitterに連絡をくださると嬉しいです。