並列処理 -入門 並列処理をCPUの歴史から理解-
以前PubChemから膨大な量の化合物のリストを取得しました。
名前とIDだけを抜き出しましたが、約1億5千万の単語数、JSONファイルにして17GBになりました。
これを使ってマッチングを試そうとしましが、ファイルの読み込みだけで12時間かかりました。
こりゃいかんと相棒がconcurrent.futuresのProcessPoolExecutorとPandasを導入したところ10分になりました。
72倍速!すごい!
(後でわかりましたが並列化よりもPandasを導入した方が影響力が大きかったみたいです)
恥ずかしながら並列処理に関して無知だったのでまとめました。
目次
はじめに
並列処理に対してこの程度のレベルの認識しかなかった人間が勉強してまとめた内容です。
お察しください。
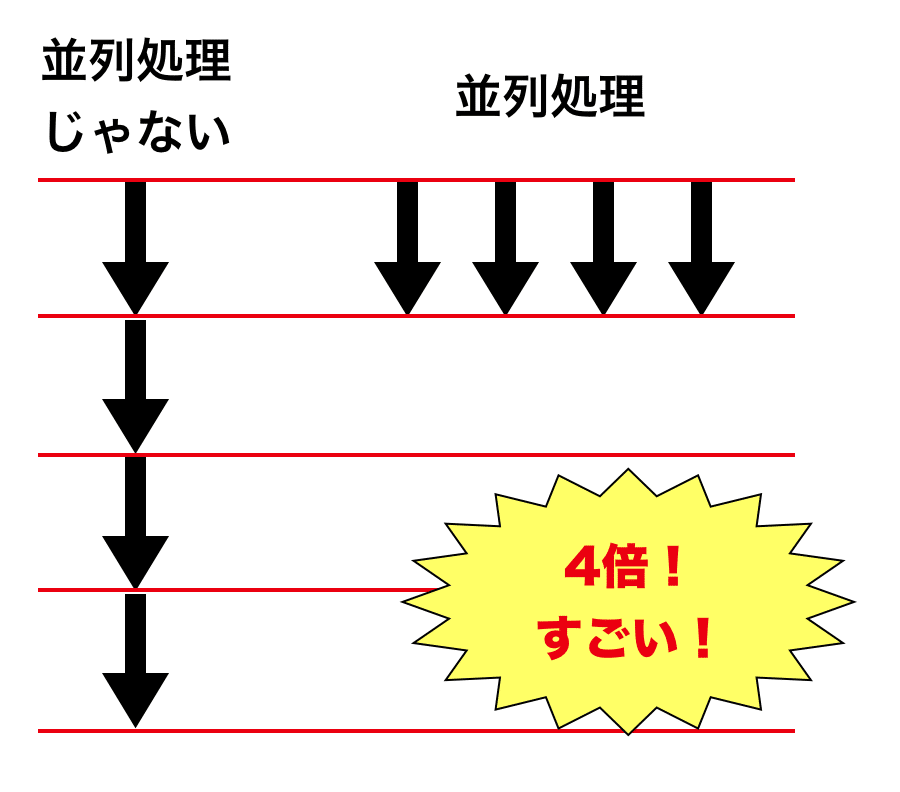
並列処理じゃない処理!
逐次処理とか直列処理とか言われるみたいです。
シーケンシャルな処理という表現も見かけました。
CPUの歴史 -シングルコアからマルチコアへの変遷-
CPU(プロセッサ)が登場したとき当然コア一つのシングルコアが主流でした。
2005年までCPU自体の性能、クロック周波数が順当に向上していきました。
しかしクロック数の増加は消費電力や発熱などの課題があり頭打ちになりました。
1コアの性能限界が見えてきたわけです。
そこでプロセッサメーカはコアの高性能化からマルチコア開発へと舵を切ることとなりました。
一つのプロセッサの中に複数のコアを入れることにしたのです。これがマルチコア(これに対して複数のプロセッサが入っているのがマルチプロセッサ)。
以降現在までデュアルコア、クアッドコアとコア数の増加を続けています。
シングルコアの時代はCPUの性能の向上の恩恵を黙っていても受けることができました。
単純にプログラムの実行速度が早くなるからです。
一方、マルチコアでは複数のコアを適切に利用するよう並列計算を意識したプログラミングをしなければいけなくなりました。
Hyper Threading Technology
Hyper Threading Technologyとはシングルコアを仮想的にマルチコアとして認識する技術です。
プロセスとスレッド
ここでコンピュータの仕事の単位としてのスレッドとプロセスについて解説します。
(Apacheの設定の時にちゃんと理解していなかったので復習。)
プロセス
プログラムの実行単位がプロセスです。
プロセス間はメモリを共有できません。並列処理の最中に使う変数はプロセスの数だけコピーする必要があるので、メモリを圧迫しないよう注意が必要です。
しかし逆に、メモリを共有しないおかげで個々のプロセスで同じ変数を書き換えてしまうことがないという利点もあります。
プロセスはコアの数だけ増やすことで並列処理を行うことができます。
スレッド
スレッドはプロセスの中の実行単位です。
シングルスレッドは一つのプロセスにスレッドが一つ、マルチスレッドは複数です。
スレッド間はメモリを共有することができます。これによってスレッドセーフであることを意識しなくてはなりません。
並列処理と並行処理と分散処理
概念的には「並列処理 ⊂ 並行処理」であるそうです。
並行処理という大きな括りの中に並列処理があるという感じ。
以下の記事が参考になりました。
並行処理
並行処理は複数のプロセスが実行可能状態であるということらしいです。
つまり厳密に同時にプロセスが動いていなくても、ユーザ側から任意のタイミングで切り替えられることが並行処理です。
マルチタスクOSを考えるとわかりやすいです。
Chrome、Slack、Itunesなど複数のソフトを同時に開いていた場合、マルチタスクOSではそれぞれのプロセスを高速に切り替えながらコアに割り振っています。
そのためユーザからは「同時」に動いているように見えます。これが並行処理です。
並列処理
一方並列処理は厳密に同時に処理されていることを示します。
並列処理が有効な問題はどのような問題でしょうか。
IBMの「並行処理から並列処理へ」という記事の例を使わせていただきます。
以下の問題では、g(n)がg(n-1)の計算結果を必要としています。
g(0) = f(0)
g(n) = f( g(n-1) ), for n > 0
構造的にシーケンシャル(逐次的)な処理をしなくてはなりません。
このような問題では並列処理を有効に適用することはできません。
一方で、以下のような問題ではf(0)、f(1)、…をそれぞれに求めるてから和を出すことができます。
このf(x)の処理を並列に処理すれば高速化が期待できます。
h(n) = f(0) + f(1) + .. + f(n)
分散処理
並列処理は1つのコンピュータ中の複数コアで同時に計算を行うことでした。
分散処理は複数コンピュータに跨って計算を行うことです。
サーバの処理性能を高くする(スケールアップ)よりもサーバの数を増やす(スケールアウト)方が安く済むのが利点です。
Python 並列処理モジュール
並列処理にはマルチプロセスとマルチスレッドがあります。
プロセスとスレッドについては上述の通りです。計算が必要な処理はマルチプロセスが有効です。
concurrent.futuresモジュール、multiprocessingモジュール、threadingモジュール、joblibモジュールなどがあります。
サンプルコードを実行しながら比較してみます。
素数かどうか判定するプログラムを参考にします。
マルチプロセス
マルチプロセスはCPUに負荷がかかるような作業で効力を発揮します。
以下のようにPRIMESリストに含まれた数字が素数かどうか判定する、という処理を実行してみます。
素数の数を2倍にして差が出やすいようにしています。
今回の検証は以下の環境で行います。
- Mac book Pro (Retina, 15-inch, Mid 2015)
- mac OS Sierra
- 2.8 GHz Intel Core i7
- 16 GB 1600 MHz DDR3
クアッドコアなので物理的なコア数は4つですが、先述のHyper Threading Technologyによって8コアとして扱えます。はずです。
比較対象: 逐次処理
特になんの工夫もなくシーケンシャルに計算します。
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]*2
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
for number, prime in zip(PRIMES, map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
timeコマンドで時間を測定します。
$ time python normal.py 112272535095293 is prime: True ... real 0m5.995s user 0m5.888s sys 0m0.040s
timeコマンドのrealは実際にかかった時間。userはCPUの稼働時間です。
逐次処理では実時間とCPU稼働時間は同じくらいですね。
マルチプロセス①: concurrent.futures ProcessPoolExecutor()
マルチプロセスを実装します。
引数は以下の通り。
ProcessPoolExecutor(max_workers=None)
max_workersは指定しなければプロセッサ数が使用されます。
Mac Book Proはクアッドコアなのでmax_workersは8が採用されるはずです。
import concurrent.futures
import math
PRIMES = [...]
def is_prime(n):
....
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
$ time python concurrent_ppe.py 112272535095293 is prime: True ... real 0m1.773s user 0m5.827s sys 0m0.062s
実時間が明らかに早くなっていますね。CPU時間は変わらないので複数のコアに仕事を割り振ったんだろうと想定できます。
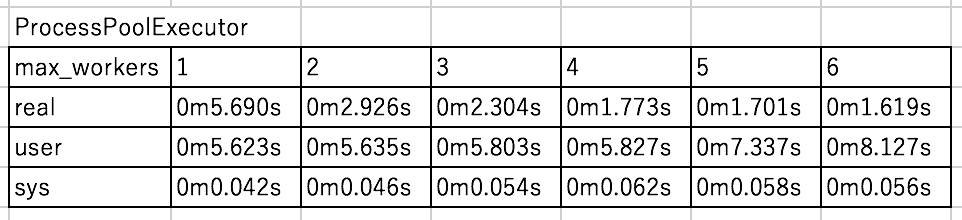
以下にmax_workersを変えてみた結果です。
4までは順調に早くなっていますが、それ以上増やしても変わっていません。
ハイパースレッディングテクノロジーで8コアとして扱えると思ったのですが、どうやら4つまでしか有効活用できていないみたいです。
色々試しましたが、やはりmax_workers増やして速度が速くなるのは4が限界みたいでした。
マルチプロセス②: multiprocessing
multiprocessingを使った書き方は以下の通り。Pool()の中に使用するコア数を指定します。
from multiprocessing import Pool
import math
PRIMES = [...]*2
def is_prime(n):
....
def main():
p = Pool(4)
for number, prime in zip(PRIMES, p.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
p.close()
if __name__ == '__main__':
main()
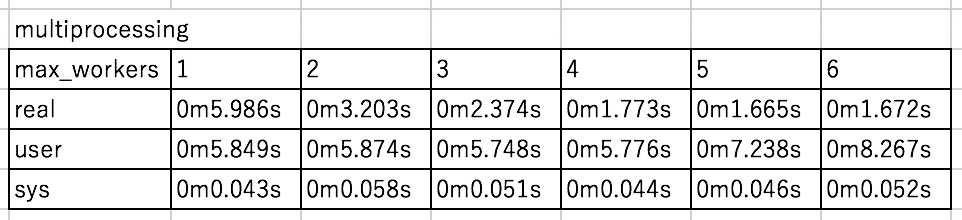
結果はこんな感じ。
マルチプロセス③: joblib
joblibは標準ライブラリではないのであらかじめpipでインストールする必要があります。
以下のようにn_jbsに利用するコア数を記述します。
from joblib import Parallel, delayed
import math
PRIMES = [...]*2
def is_prime(n):
...
def main():
for number, prime in zip(PRIMES, Parallel(n_jobs=4)([delayed(is_prime)(x) for x in PRIMES])):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
結果はこんな感じ。
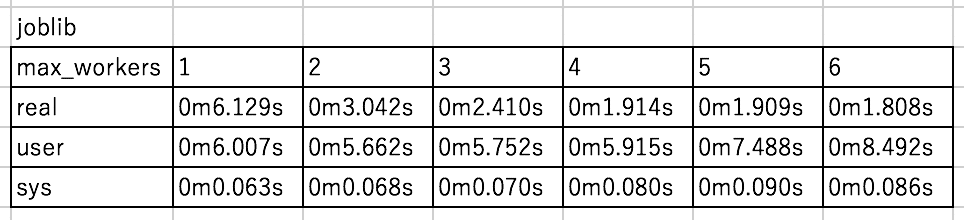
比べてみましがあまり変わらないですね。
若干joblibが遅い?書きやすいのを使えばいいと思います。
おまけ CPUのコア数の取得
os.cpu_count()でシステムのコア数を取得できます。
これで取得するとMac book Proのコア数が8つと認識されているらしい。
現在利用可能のコア数の取得にはlen(os.sched_getaffinity(0))を使います。
マルチスレッド
マルチプロセスはCPUのリソースを食うものの並列処理に適していました。一方でマルチスレッドはCPUリソースを消費しないもの、例えば外部へのアクセスなどに適していると言われています。
時間ができたらまとめます。
クラウドの選択肢
参考
- Pythonのconcurrent.futuresを試す | takuti.me
- マルチコア CPU が並行処理にもたらす変化
- 【CPUの基本】図解でよくわかる「マルチコア / スレッド」の意味 | ちもろぐ
- CPU選びの基本:マルチコアとマルチスレッド
- 「マルチコアプロセッサ」と「マルチプロセッサ」の違い|「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典
- プロセスとスレッドの違い – Wake up! Good night*
- イケてるエンジニアになろうシリーズ 〜メモリとプロセスとスレッド編〜 – もろず blog
- 並列計算 – Wikipedia
- Java Streams, Part 4: 並行処理から並列処理へ
- 並列計算の概念(プロセスとスレッド)
- 第3回 プロセスとスレッド:Windows OS入門 – @IT
- ITエンジニアの「やってはいけない」 – [実装編]スレッドセーフにすることを忘れてはいけない:ITpro